Discussion
The present thesis investigated the role of orthography in novel spoken word learning. Specifically, we asked whether orthographic knowledge, which comprises sound-to-spelling conversion rules, impacts the acquisition of novel phonological representations by converting them into orthographic ones. Stuart and Coltheart (1988) proposed that children can make use of their orthographic knowledge to form preliminary orthographic representations (i.e., orthographic skeletons) for aurally familiar words, and that, even before seeing the words’ real spellings. This idea, and in particular, the link between orthographic knowledge and spoken word learning, had been investigated in several studies employing novel word learning paradigms. Johnston and colleagues (2004) for instance, showed that adult English speakers were able to encode initial orthographic representations of newly acquired spoken words. In a masked priming paradigm, which taps into unconscious and automatic processes (Forster & Davis, 1984), they observed significantly faster reading times for aurally acquired words preceded by identical primes (e.g., e.g., <spathe> before <SPATHE>) as compared to those preceded by purely phonological primes (e.g., <spaith> before <SPATHE>). More recently, Wegener and colleagues (2018, 2020) manipulated novel words’ spellings, and showed that when first encountered in print, aurally trained words with predictable spellings were read faster than words with unpredictable spellings. By demonstrating that orthographic representations can be generated even in the absence of orthographic input, these studies provided some of the first evidence for the account proposed by Stuart and Coltheart (1988). Nevertheless, they left open several important questions regarding the process underlying the creation of these preliminary orthographic representations. Firstly, from the existing research it remained unclear whether orthographic skeletons are generated for all aurally acquired words, regardless of the number of possible spellings, or only for words with a unique and thus completely predictable spelling. Moreover, as all studies had been done in English, a language with highly inconsistent both spelling-to-sound and sound-to-spelling mappings, one could argue that the observed results may be specific to languages resembling English. Given that English speakers are used to encountering inconsistent and unpredictable spellings, generating orthographic skeletons may be a process specifically developed by their cognitive system in order to ease the reading of new printed words. Finally, and in line with the previous point, none of the previous studies was able to say anything about the nature of the process by which orthographic skeletons are generated. In particular, it remained unclear whether the observed effects were due to participants’ personal strategies, or whether they were driven by a process inherent to the cognitive system which gets developed once sound-to-spelling conversion rules had been acquired. These questions were thus explicitly tested in the present thesis.
Across three experiments we showed that aural training with novel word forms prompted skilled readers to use their knowledge of sound-to-spelling mappings to generate preliminary orthographic representations. Importantly, we saw that these orthographic skeletons are generated before the first visual encounter with words’ actual spellings. Moreover, we described the conditions under which orthographic skeletons are generated, as well as factors that influence their creation. In the first experiment we showed that orthographic skeletons are generated even when there is uncertainty regarding the correct spelling. When first confronted with novel words’ spellings, Spanish skilled readers showed no differences in reading aurally familiar words with unique and those with two possible spellings,. However, this was the case only when the latter were shown in the preferred spelling option. We took this finding as evidence that these Spanish speakers had indeed generated orthographic skeletons for all previously acquired spoken words (both for words with a unique as well as those with two possible spellings).
In the second experiment we replicated the findings from Experiment 1 and showed that orthographic skeletons for words with more than one possible spelling are generated even in a language in which the overall probability of generating an incorrect representation is high (i.e., French). Since the probability of generating an incorrect representation is higher in French than in Spanish, one could argue that generating orthographic representations even under uncertainty (i.e., for words with multiple legal spelling options) may be specific to consistent languages. By replicating the results observed with Spanish speakers, we showed that it is not the case and that orthographic skeletons for words with multiple spellings can indeed be generated even in a highly inconsistent language.
Finally, in Experiment 3 we investigated the nature of the orthographic effects in spoken word learning. More precisely, we asked whether generating orthographic skeletons represents an automatic (unconscious) or voluntary (conscious) process. Although they are not conclusive, due to relatively small sample size, our data suggest that orthographic effects in spoken word learning may very much be driven by participants intentions, and are therefore voluntary rather than automatic in nature. This finding thus implies that although orthographic skeletons are generated for all aurally acquired words, they may actually be generated only when doing so can help participants in the (explicit) word learning process.
Theoretical and practical implications
Findings from the three experiments conducted in the course of the present thesis have important theoretical and practical implications for both reading development theories, as well as word learning research. We will start by first discussing our findings in the light of previous research. Importantly, we will highlight what the present thesis adds to what we already know about the relationship between orthography and phonological processing. Finally, we will propose several ideas on how these findings could be used to bridge the gap between theoretical and practical work in both reading development and novel vocabulary acquisition.
Consequences of generating orthographic skeletons for word reading
The orthographic skeleton hypothesis was initially developed with the aim to explain the observed (positive) link between oral vocabulary knowledge and word reading success (see Wegener, Beyersmann, Wang, & Castles, 2022). According to the previous accounts of reading acquisition and development, orthography exerts its effects on word reading at the moment of the first visual encounter with the aurally familiar word’s spelling. This occurs either via orthographic learning (Castles & Nation, 2008) or phonological decoding (Share, 1995). The orthographic skeleton hypothesis however, goes a step further by claiming that orthographic influence can begin even before the first visual encounter with aurally familiar words’ spellings. Through sound-to-letter conversions, aurally familiar words get converted into preliminary orthographic representations. These representations are generated during the learning phase and are then held in lexical memory, similarly to existing orthographic representations of already familiar words. Importantly, these representations are malleable and can be modified upon visual encounter with words’ actual spellings (Wegener et al., 2020). Due to the existence of these preliminary orthographic representations, the first time a reader is confronted with a word’s spelling, reading should be facilitated, but only when the representation in the lexical memory matches the presented spelling. The work presented here further shows that representations in the lexical memory are influenced by personal spellings preferences rather than statistical properties fo the writing system (see Figure 3.7).
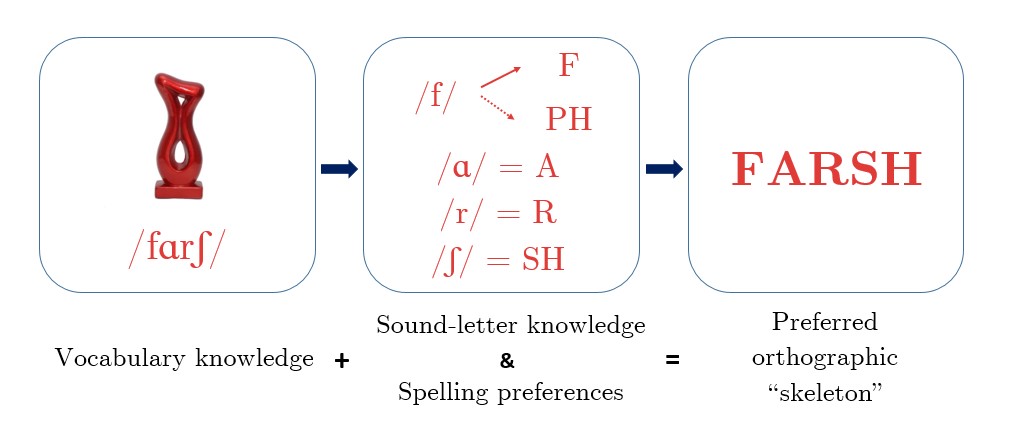
Figure 3.7: Updated Representation of the Orthographic Skeleton Hypothesis. Having a word in the oral vocabulary and knowing how sounds map onto letters will lead to the creation of a preliminary orthographic representation (i.e., the orthographic skeleton). Importantly, orthographic skeletons for words with more than one possible spelling will be in line with personal spelling preferences.
The present thesis expands on the orthographic skeleton account by showing that the consequences of generating orthographic skeletons for subsequent word reading may actually be dependent on the properties of the writing system, and in particular, the overall sound-to-spelling consistency. The pattern of results observed in Experiment 2, which was conducted with French speakers, follows that of English speakers reported by Wegener et al. (Wegener et al., 2018, 2020). In French and English, which are both opaque languages, reading was facilitated when presented spellings were in line with orthographic skeletons participants had previously generated. The pattern of results observed with speakers of a transparent language such as Spanish (Experiments 1 and 3), was however, somewhat surprising. Namely, the two studies done with Spanish speakers demonstrated that aural training does not necessarily lead to reading facilitation, since no differences in reading trained and untrained words with unique and preferred spellings were observed. This absence of the training advantage in Spanish was explained as stemming, at least partly, from the transparency of the Spanish writing system. As previously discussed, speakers of a transparent language such as Spanish have more experience with encountering spellings in accordance with their expectations. Being confronted with spellings that do not match their predictions could thus lead to slower reading times (i.e., a surprisal effect). By contrast, speakers of opaque languages such as English and French are less often presented with correctly predicted spellings. The surprisal effect could therefore be expressed as a significant facilitation for words that do match their predictions. Based on this reasoning and the work presented here, we can conclude that that generating orthographic skeletons is actually more beneficial in inconsistent languages.
The cross-linguistic differences reported in this thesis should thus be incorporated into the existing theoretical accounts aiming to understand the positive, and according to some, causal link between oral vocabulary knowledge and word reading McKague et al. (2001). Work by Wegener et al. (Wegener et al., 2018, 2020), as well as the results from Experiment 2, show that this link could indeed be supported by a mechanism leading to the creation of orthographic skeletons, in speakers of opaque langues. However, data obtained in the two studies done with Spanish adult speakers not only failed to replicate the positive influence of aural training on word reading, but they showed that in a transparent language generating orthographic representations can actually hinder subsequent reading. Although the absence of the aural training advantage may have been caused by experimental material (e.g., relatively simple and short words), we should not exclude the possibility that in adult speakers of transparent languages, aural training does not necessarily come with an advantage. On a more practical level, these findings could be used to improve reading instructions and interventions. Given that generating orthographic skeletons seems to be under voluntary control, both children as well as adults learning to read in an opaque writing system should be encouraged to generate orthographic skeletons not only when learning novel spoken words, but for already familiar words as well. Of course, more research on speakers of languages with consistent language systems (e.g., Italian or German), is needed to confirm these conclusions regarding the observed cross-linguistic differences, and any reading instructions and/or interventions should be designed accordingly.
Consequences of generating orthographic skeletons for word learning
Although the main motivation behind the orthographic skeleton account was not to describe the word learning process per se, but rather its relationship with reading, the present data provide new insights into how novel vocabulary is acquired in the auditory domain. In the first place, along with the two studies conducted by Wegener and colleagues (Wegener et al., 2018, 2020), findings from the present thesis show that once orthographic code is acquired, both children and adults can make use of it during spoken word learning. This means that in addition to learning a novel phonological representation, the concept it refers to, the link between the two and finally integrating the word in the network of already existing words (McMurray et al., 2016), learning a new word may include an additional step. The additional step would consist of generating orthographic analogs of the acquired phonological word forms, but only when the words are acquired via explicit instruction. Our results thereby expand on those reported by Ehri and Wilce (1979). In their seminal study, Ehri and Wilce (1979) showed that linking orthography to novel phonological word forms facilitates the learning process. This orthographic facilitation was present even when participants were not exposed to words’ spellings, but were instructed to imagine them. Ehri and Wilce (1979) thus concluded that the instruction prompting participants to imagine words’ spellings (i.e., visual representations of novel words) resulted in an additional memory cue aiding the learning process. The work presented here shows that during spoken word learning, participants generate visual representations of novel words - in the form of preliminary orthographic representations - even when they are not explicitly instructed to do so, but when generating spelling expectations can be of help and facilitate the learning process.
By showing differences in reading novel words acquired through explicit as compared to those acquired through implicit aural instruction, findings from the present thesis provide novel insight into the mechanisms underlying these two types of learning. Whereas explicit training with novel spoken words resulted in the creation of orthographic skeletons, the same training in the implicit learning context did not. Previous research reported several advantages of explicit over implicit instruction. Of particular interest for the present thesis are the findings showing faster establishment of novel lexical representations acquired trough explicit learning (Batterink & Neville, 2011; Sobczak & Gaskell, 2019). Since orthographic skeletons represent an additional memory cue promoting the learning process, generating them may be one of the reasons leading to the superiority of the explicit as compared to implicit learning. Future research could thus set out to test the causal role of generating orthographic skeletons in the faster acquisition of novel lexical representations during explicit learning.
Interestingly, our data show that participants vary considerably in their ability to generate orthographic skeletons, since differences in reading unpreferred and unique spellings were not uniform in any of the three experiments. Although the sample size in each of the studies is not large enough to make any strong conclusions regarding the individual differences, the two exploratory analyses we performed with the aim to better understand the consequences of generating orthographic skeletons, show that participants with larger surprisal effects also show better retention of the words they were trained on. In addition, we show that good phonological short-term memory skills alone, which have been so far considered the main predictor of spoken word learning success (Gathercole, 2006), may not be enough to explain individual variability in novel word recall. These individual differences could stem from the quality of orthographic representations (in this case orthographic skeletons) participants generated during the learning task (Perfetti & Hart, 2001; Perfetti, Wlotko, & Hart, 2005). Participants with incomplete or vague orthographic representations had less cues to hold on to when recalling the novel words, which would explain their lower accuracy on the picture naming task (see Ehri & Wilce, 1979). This reasoning is supported by a post-hoc exploratory analysis performed on data from Experiment 1. To explore whether participants who were more consistent in their spelling preferences, meaning that they invariably preferred one grapheme over the other (e.g., always chose letter <b> over <v> for inconsistent words starting with the phoneme /b/, or grapheme <ll> over <y> for items whose initial phoneme was //) exhibit a somewhat different pattern of results than those participants varying in their preferences (e.g., for some items they chose <b> while for the other they preferred <v>). To that end, each participant was awarded a consistency score (higher scores indicated more consist spelling patterns) and the entire sample was then divided in two groups through a median split. Surprisingly, the orthographic skeletons effect (i.e., the difference in reading times between trained words with unique and those with unpreferred spellings) was larger in the group of participants who tended to vary in their spelling preferences. This suggests that participants who were less consistent in their preferences for words with two possible spellings are those who were more likely to create orthographic skeletons. One possible explanation of this finding, in line with the Lexical Quality Hypothesis (Perfetti & Hart, 2001), would be that participants who tend to vary in their spelling preferences think more about possible spellings of the novel words they are presented with and how god of a fit is a particular grapheme in a particular word. In other words, these participants generate more solid orthographic skeletons which would lead to larger orthographic skeleton effects as well as better recall of the novel words. By contrast, participants who tend to hold on to one particular letter across all words, might do so as it is less demanding. They may therefore be less prone to think about and imagine the possible spellings of these novel words, and thus generate vague orthographic representations. Consequently, they would not show strong orthographic skeleton effects and would not have good visual cues when recalling the words. However, the observed individual differences in generating orthographic skeletons related to phonological short-term memory (PSTM) skills could also be interpreted the other way around. That is, participants with better PSTM skills are able to create better visual memory traces in the form of preliminary orthographic representations in their episodic memory. This would lead to both better word reading as well as larger orthographic skeleton effects. This interpretation is supported by EEG data showing individual differences in word learning related to reading comprehension skills (Perfetti et al., 2005). In a novel word learning study, Perfetti and colleagues (2005) showed that participants with better reading comprehension skills, generated better memory traces for newly acquired words as indicated by their stronger episodic memory effects at around 400-600ms after written word onset. Importantly, they were also better at learning novel words as compared to less skilled comprehenders. These findings thus show that both reading skills and memory capacity are important for novel word acquisition. Future researcher is however needed in order to explore the origin of the relationship between the two, and specifically, test whether one is a necessary precursor of the other.
Finally, all previous studies had been done with L1 speakers, who were tested in their first and most dominant language. Acquiring oral language skills in one’s native language almost always precedes the acquisition of reading and writing. By contrast, in second language(s) (L2), which are acquired later in life, and most often in a classroom context, the two skills are usually developed in parallel. It could therefore be the case that orthographic effects in spoken word learning may actually be stronger in an L2, since oral and written skills attain a more equal status in languages acquired in a classroom setting. This prediction is supported by findings reporting positive effects of orthographic exposure on novel form word learning in an L2 (Bürki et al., 2019). When trained on novel word forms presented either in their auditory form only or along with their spellings, French L1 learners of English showed better learning outcomes (i.e., fewer errors and faster naming times) for words learned in both auditory and orthographic forms. Therefore, orthography as a mnemonic tool could explicitly be used in second language instruction. L2-learners could be prompted to create orthographic representations every time they learn a novel spoken word, despite the possibility of creating an incorrect representations, since this would give them a more solid memory cue of a newly acquired word.
Orthographic effects in spoken language processing
Apart from better understanding the link between oral vocabulary knowledge and word reading, the work conducted in the course of this thesis also aimed to expand on the previously reported orthographic effects in spoken word processing. To test whether orthographic knowledge affects spoken language processing, and specifically, speech perception, a vast amount of previous research has made use of sound-to-spelling (in)consistencies and has tested differences in recognition of words with one, as compared to those with multiple possible spellings. Faster recognition times for spoken words with unique spellings obtained in various different languages (French, English, Portuguese and Spanish) as well as populations differing in their reading skills (children and adults), were taken as evidence that, once acquired, orthography indeed changes the perception of spoken words (Chéreau et al., 2007; Pattamadilok et al., 2009; Ventura et al., 2004; Ziegler & Ferrand, 1998).
The three experiments presented here, along with the work by Wegener and colleagues (Wegener et al., 2018, 2020), add to this line of research by revealing another way in which orthography can influence speech perception. By teaching participants spoken words with one or two possible spellings, we show that orthographic knowledge can lead to the creation of orthographic representations of novel words never seen in writing. Importantly, data from Experiment 3 suggest that orthographic effects may sometimes be driven by participants’ strategies rather than being completely automatic in nature. This contrasts with the previous work on speech perception. Even though they still debate on whether orthographic effects are due to the automatic co-activation of orthographic representation during speech perception (Chéreau et al., 2007), or whether existing phonological representations get modified during reading acquisition (Muneaux & Ziegler, 2004; Perre et al., 2009), previous studies showing orthographic effects in speech perception agree that the observed effects are not under participants’ control. Replicating the pattern of results from Experiment 1 only in the group of active learners from Experiment 3, that is, learners who were aware of the learning process, suggests that the orthographic effects seen in spoken word learning could actually be strategic. This findings implies that the bi-directional links between phonological and orthographic representations may under some circumstance be sensitive to top-down influences.
Future directions
The three experiments presented here were carefully planned and designed to test three very specific research questions. Consequently, we tried to control for all confounding variables that could potentially mask the effects we were interested in. That being said, it is important to outline the limitations of the present work with the aim to motivate future research and hence broaden our knowledge on the link between orthography and auditory word learning.
Firstly, all our conclusions are based on the assumption that the reported effects of aural training on the subsequent word reading emerge because participants generated preliminary orthographic representations during the learning phase. This thus implies that the newly acquired orthographic representations must have been kept in lexical memory, along with the already existing representations of familiar words. Nevertheless, another equally possible explanation of the presented results is in line with the aforementioned accounts postulating that the effects of aural training on word reading are taking place at the moment of the first visual encounter. According to this alternative explanation, orthographic representations are not generated during the learning process and then retained in the mental lexicon, but are rather generated at the first visual encounter with novel words’ spellings. Specifically, it could be the case that when first confronted with the written form of an aurally familiar word (e.g., <vadi>), a phonological representation of this word is automatically generated. This phonological representation would match the one generated during aural training, and at the same time activate its preferred orthographic form. The latter, being in line with the actual spelling, would facilitate word recognition. By contrast, the newly created orthographic representation might not overlap with the spelling leading to its slower recognition. Having said that, it is important to note that the predictions derived from this alternative hypothesis do not differ from those implied by the orthographic skeleton hypothesis. This makes it difficult, if not impossible, to adjudicate between the two given the data we have obtained so far. In order to show which of the two mechanisms (if not both at the same time), is more likely to be taking place during the first visual encounter with aurally familiar words, future research should turn to more precise and online measure of language processing such as EEG or eye-tracking. In addition, formulating computational models which able to simulate the observed data (see below) would help better describe the underlying process driving the observed orthographic effects.
Another important consideration to take into account is the level of reading skills needed to generate orthographic skeletons, and in particular, to generate them for all aurally acquired words regardless of the number of possible spellings. The data we present here may be limited to skilled readers. Due to their vast experience with written language (in the form of reading and writing), skilled readers may be impacted by orthography more than children. Consequently, they might be more prone to generating orthographic skeletons for all novel words, even for those whose spellings were uncertain. By contrast, early and developing readers lack the reading expertise and experience with orthotactic probabilities present in skilled readers. As a result, they may generate orthographic skeletons only when a single highly probable spelling is available (i.e., only for words with unique spellings). Future research could set out to test children at different stages of reading acquisition in order to provide more insight into the developmental trajectory of the mechanism responsible for generating orthographic skeletons. This way we would be able to determine the extent to which the orthographic skeleton hypothesis can be generalized to different populations (i.e., early readers).
In addition, the findings we observed may also be specific to readers who successfully acquired sound-to-spellings correspondences (i.e., normally-developing readers). Since generating orthographic representations requires good phonological and orthographic processing skills, readers with dyslexia, who have difficulties with both, may actually not be able to generate orthographic skeletons as a result of aural training. Indeed, previous research has shown that both phonological and orthographic representations tend to be deficient in this population (Cao, Bitan, Chou, Burman, & Booth, 2006; Elbro & Jensen, 2005; Hasko, Bruder, Bartling, & Schulte-Körne, 2012). Moreover, children with dyslexia usually need more time to create associations between novel phonological representations and novel semantic concepts (Elbro & Jensen, 2005). Generating orthographic skeletons may thus require more extensive training with spoken words in readers with reading difficulties such as dyslexia. However, since this group particularly struggles with phonological decoding, which consists of mapping orthographic input into already existing phonological representations, extensive aural training with novel phonological word forms may be beneficial. Generating any kind of prior orthographic representations would help decoding the words when they are first encountered in print. Therefore, adapting the tasks used in the present thesis so they could be used to test readers with dyslexia could result in the creation of new reading interventions.
Finally, although we tried to describe the mechanism(s) by which orthographic skeletons are generated during spoken word learning as thoroughly as possible, experimental work alone is limited when it comes to building complete theoretical accounts. To better understand the exact processes underlying the creation of orthographic representations during spoken word learning, a formal computational model able to account for the observed data, as well as simulate future outcomes, should be formulated (see Rooij, 2022, for the importance of models in understanding the phenomena studied in experimental psychology). Such a model would have to be complete (describe and define all mechanisms involved in the process of generating orthographic skeletons) and sufficient (able to account for all the observed data taking into account the properties of each writing system). As a result, the model would be able to generate predictions that would then be tested against participants behavior, this way advancing the theoretical framework. A first step in this direction could be to try to incorporate the present data into already existing model structures (e.g., the TRACE model; McClelland & Elman, 1986) by tweaking some parameters specific to the studied phenomenon. This would give an overview of the processes which are underspecified and hence need to be redefined.
Conclusion
The present thesis investigated the role of orthography in spoken word learning. To that end, we tested whether the previously observed positive link between oral vocabulary knowledge and word reading could be mediated by a mechanism responsible for converting newly acquired phonological representations into orthographic ones even before the first visual encounter with the words’ actual spellings. Across three experiments we show that skilled readers do generate preliminary orthographic representations (so-called orthographic skeletons) for newly acquired spoken words. Importantly, our work provides some of the first evidence that orthographic skeletons are generated even when there is uncertainty regarding the correct spelling, as is the case when multiple spelling options are possible. Moreover, we show that orthographic skeletons are generated in languages with fairly consistent writing systems (e.g., Spanish), but also those with more complex sound-to-spelling correspondences, in which the overall probability of generating an incorrect representation is higher (e.g., French). Finally, our data seem to suggest that generating orthographic skeletons may not be an automatic process inherent to the cognitive system, but could actually be driven by participants’ personal strategies. Overall, the present thesis adds to the previous literature by describing new ways in which orthographic knowledge affects spoken language processing.