Chapter 3 The nature of orthographic effects in spoken word learning
Work presented in this chapter is based on:
Jevtović, M., Kapnoula, E.C., and Martin, C.D. (in preparation). Implicit versus explicit creation of spelling expectations during auditory word learning
3.1 Introduction
So far we have presented data showing that aural training with novel spoken words leads to the creation of orthographic skeletons (i.e., preliminary orthographic representations). In addition, we demonstrated that, although they have different consequences for subsequent word reading, orthographic skeletons are generated both in a language with relatively low level of spelling uncertainty (e.g., Spanish; see Experiment 1) as well as in a language with higher level of spelling uncertainty (e.g., French; see Experiment 2). In Spanish, a language with highly consistent sound-to-spelling mappings, generating orthographic skeletons leads to an inhibitory effect. Conversely, generating such representations in a language with overall higher probability of generating an incorrect representation (due to inconsistent sound-to-spelling mappings), seems to be beneficial as it results in a facilitatory effect. These findings showing that orthographic skeletons are generated even when there is a risk of error, could be interpreted as showing that engaging in the process of generating orthographic skeletons does not entail a high cognitive cost, and may therefore be automatic in nature. However, these two experiments were not designed to test the nature of the mechanism by which orthographic skeletons are generated. Therefore, it remains unclear whether this mechanism is automatic or maybe even voluntary in nature. In the final experimental chapter of this thesis we directly test the nature of the mechanism responsible for sound-to-spelling conversion during auditory word learning. We do so by testing whether generating orthographic skeletons results from an unconscious, and hence automatic process, or whether orthographic skeletons are generated as a result of a strategic process consciously initiated by participants with the aim to facilitate novel word learning. Understating the nature of this converting mechanism would not only add to the orthographic skeleton account, but would help us better understand the nature of the orthographic influence on spoken language processing.
As discussed in the Introduction, studies looking into the role of orthography in word learning, mainly focused on exploring whether presenting orthographic labels along with novel phonological forms has a facilitatory effect on the learning process. In these studies, novel words’ spellings were thus explicitly presented during the learning process, and participants could use them as an additional memory cue easing the acquisition of novel vocabulary. Ehri and Wilce (1979) were the first to show that explicitly linking orthographic labels to novel phonological representations comes with a learning benefit in early readers (see also Rosenthal & Ehri, 2008). In their study, first and second grade children were both faster and more accurate to acquire novel vocabulary when both spelling and sound were present during the learning phase. These findings were later expanded to both older children (i.e., eight and nine-year-olds; see Ricketts, Bishop & Nation, 2009) as well as adults (Nelson et al., 2005). Interestingly, the orthographic facilitation observed by Ehri and Wilce (1979) occurred not only when spellings were explicitly shown during the learning phase, but when children were instructed to imagine novel words’ spellings as well. To explain this learning advantage present in the absence of orthography, the authors argued that the instructions children had received prompted them to generate words’ spellings by forming visual images during the learning phase. In return, these visual images, in the form of words’ spellings, facilitated the acquisition of novel phonological forms just as if they had been explicitly present during the acquisition process.
With these findings in mind, and in particular, the one showing that orthographic facilitation occurs even in the absence of orthography, one could argue that the effects observed both in our, as well as the two studies conducted by Wegener et al. (Wegener et al., 2018, 2020), resulted from a strategic process participants had initiated with the aim to facilitate the learning process. Although orthography was not present during the learning process in the previous two experiments, and participants were not told they would later be presented with words’ spellings, they were supposed to learn the novel phonological word forms they were presented with. That is, participants in both of these studies knew they were in a situation of explicit learning. Consequently, they could have relied on their knowledge of phoneme-to-grapheme correspondences to generate additional learning cues, in the form of a preliminary orthographic representations. These orthographic representations would then help them learn the novel words. By contrast, based on the reasons described in the previous paragraph, and which have to do with cross-linguistic differences observed so far, the other possibility according to which orthographic skeletons result from an automatic and involuntary process is also plausible. This is indeed what some studies showing orthographic effects during spoken language processing would argue for. Specifically, since in some tasks relying on one’s orthographic knowledge actually comes with a disadvantage (Castles et al., 2003), orthographic effects may very well be involuntary (i.e., automatic). To adjudicate between these two possibilities, we conducted a study in which the creation of orthographic skeletons was compared in an active versus passive word learning context (i.e., explicit versus implicit learning). Implicit learning defined as the type of learning that occurs without conscious awareness (Reber & Winter, 1994) does not require attention to learn. Seeing evidence for the orthographic skeleton hypothesis in a passive learning context would mean that generating orthographic skeletons is an automatic rather than strategic process.
3.1.1 The present study
The goal of Experiment 3 was to test whether generating orthographic skeletons during spoken word learning occurs automatically (i.e., without participants’ conscious attention) or whether generating them results from a voluntary process participants purposely engage in with the aim to facilitate the learning process. To that end, two groups of Spanish speakers were tested reading previously acquired spoken words with either one, or two possible spellings (consistent and inconsistent words). However, while half of the participants learned the novel words through explicit learning (hereafter active learners), the other half was naive regarding the goal of the study and thus acquired the words implicitly (hereafter passive learners). Importantly, both groups completed exactly the same auditory word learning task, the only difference being the instructions they received: passive learners were told that the task was testing their ability to recognize objects presented in different sizes and coulours, while the active learners were instructed to learn all the words as their performance would later be tested (see Section 3.2.3.2).
As in the previous experiments, all participants first provided their preferred spellings for all novel words to be used in the main task (those they would later be trained on, as well as those from the untrained set). Two weeks later, they completed the aural training task right before being exposed to novel words’ spellings in a self-paced reading task. Upon completing the reading task, they went through a learning check. Note that in contrast to the first two experiments, which assessed participants’ learning accuracy before the reading task, the learning check was completed after the reading task. This was done so as not to reveal the aim of the study to the group of passive learners (i.e., if they were to see the learning check before reading, they could have realized what the aim of the study was).
Based on the findings from the experiment conducted with Spanish speakers, in the group of active learners we expected to observe a significant interaction between spelling and training driven by longer reading times only for previously acquired words shown in their unpreferred spellings. This would imply that participants had generated orthographic skeletons for all previously acquired words. That is, the pattern of results in the group of active learners should replicate the one observed in Experiment 1. Importantly however, if the process underlying the creation of orthographic skeletons is automatic (i.e., not driven by participants’ strategies) the same pattern of results should be present in the group of passive learners. By contrast, if orthographic skeletons are a result of a conscious and intentional process, the group of passive learners should not show any differences in reading previously acquired consistent and inconsistent words with unique, preferred or unpreferred spellings.
Note that we were not interested in any interactions between the two groups. Testing two groups was however needed in order to make sure that the paradigm used to test the creation of orthographic skeletons in a passive learning context is indeed appropriate and can detect any potential effects of previous aural training. Therefore, all our planned comparisons concern per group analysis.
3.2 Methods
3.2.1 Participants
A total of 64 participants with Spanish as their first and dominant language were tested in the study (see Table 3.1 for complete information about participants linguistic profile). They were randomly split in two groups (33 active and 31 passive learners). The groups were matched on their working memory capacity (\(M_{active}\) = 1.94, \(SD_{active}\) = 2.74; \(M_{passive}\) = 2.32, \(SD_{passive}\) = 1.94; t(62) = -.642, p = .523) as well as nonverbal IQ (\(M_{active}\) = 85.8, \(SD_{active}\) = 7.95; \(M_{passive}\) = 85.5, \(SD_{passive}\) = 10.7; t(62) = .089, p = .929).
Participants were recruited from the BCBL Participa database and received 20 euros for their participation in the study. The experiment was approved by the BCBL Ethics Review Board (approval number 011221SM) and complied with the guidelines of the Helsinki Declaration. All participants gave their written consent at the beginning of each of the two sessions.
| Mean | SD | Range | |
|---|---|---|---|
| AoA | 0 | 0 | 0-0 |
| Picture naming (0-65) | 64.8 | 0.46 | 63-65 |
| LexTale (0-100%) | 94.1 | 5.25 | 73.33-100 |
| Interview (1-5) | 5 | 0 | 5-5 |
| Self-rated proficiency (0-10) | |||
| Speaking | 9.78 | 0.45 | 8-10 |
| Understanding | 9.68 | 0.562 | 8-10 |
| Writing | 9.66 | 0.59 | 7-10 |
| Reading | 9.73 | 0.51 | 8-10 |
| Note. As in Experiment 1, some participants had some knowledge of a second or even a third language but none of them was highly proficient in any language other than Spanish. | |||
| a There are a total of 65 pictures to be named in the BEST (making 65 the maximum possible score). b Self-rated proficiency data are missing for three participants. |
3.2.2 Stimuli
The same novel words from Experiment 1, along with the pictures associated with them, were used in the study (see Section 1.2.2). However, in order to minimize misspellings (e.g., participants writing <chuñe> instead of <yuñe> or <lluñe> for the item /ʎuɲe/), as well as empty responses (i.e., participants leaving out the target phoneme <uñe>) observed in the pre-test spelling task from Experiment 1 (see Appendix 3.6), a novel set of audio recordings with improved quality was employed. As in Experiment 1, the recordings were made by an L1 Spanish speaker coming from the same region as the participants tested in the experiment.
3.2.3 Procedure
The experiment was organised in two sessions. During Session 1, participants first provided their preferred spelling options for all novel words to appear in the experiment in a pre-test spelling task. They then completed two linguistic distractor tasks (i.e., a lexical decision and a real word spelling task). Next, to make sure the two groups (i.e., the active and passive learners) were matched on their working memory capacity, all participants completed a working memory N-back task, followed by a pseudoword repetition task. To ensure participants were also matched on their non-verbal IQ, at the end of Session 1 they completed a three minute Raven’s Progressive Matrices task (Raven et al., 2003).
Session 2 started with the aural training task which was the same for both groups, the only exception were thus the instructions given to the participants. Right after the aural training participants completed a short distractor task (i.e., the Simon task; Simon, 1969). Next, they were presented with novel words’ spellings in a self-paced sentence reading task. Upon completing the reading task, participants were asked several questions regarding their impressions of the study. Importantly, to check whether passive learners were really naive as to the goal of the experiment, all participants were explicitly asked to describe what they think the study was investigating. To make the experiment as similar as possible to the previous two, following this short questionnaire, participants completed a picture naming task and a learning check.
An important improvement in regards to the first two experiments was that at the beginning of each session, participants completed a short headphone-check task (Woods, Siegel, Traer, & McDermott, 2017). The aim of this task was to make sure participants wear headphones throughout the experiment. On each trial they heard three consecutive sounds, and had to indicate which one was the quietest. Differentiating the loudness of the three sounds is relatively easy with headphones, but almost impossible to do without them. There were in total 6 trials and participants had to correctly respond to at least four in order to start the experiment. Otherwise, they would repeat the headphone check until reaching this criteria.
Since most of the tasks have already been presented in the previous chapters (see Section 1.2.3.1 for a description of the pre-test spelling task, and Section 1.2.3.3 for the self-paced sentence reading task) and given that nonword repetition task will not be discussed further, here we present only the tasks specific to this experiment.
3.2.3.1 N-back task
To make sure that participants from the two groups were matched on their working memory capacity, they all completed a 2-back letter task. In this task participants were presented with a sequence of letters presented one at a time, and their task was to determine whether the letter on the screen matches the letter that appeared two trials (letters) before (see Figure 3.1). Participants were instructed to respond by pressing the button ‘M’ to the relevant letter and to withhold their responses to distractor letters. Each letter stayed on the screen for 500ms and participants had additional 2000ms (blank screen) to give their response before the appearance of the next letter. There were in total 26 main and 10 practice trials. The main dependent variable was the number of correctly identified 2-back matching items.
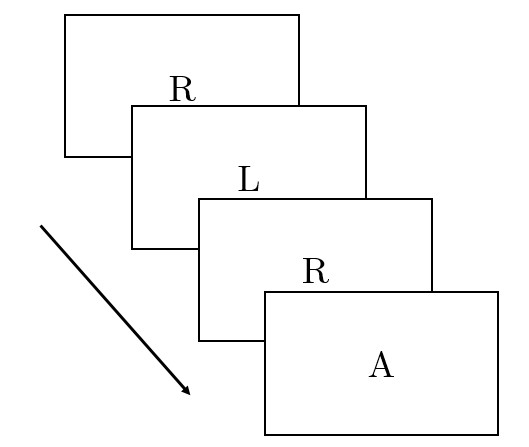
Figure 3.1: N-back task. Participants had to press ‘M’ on their keyboard only when the letter presented matched the letter presented two trials ago. In this example participants had to press ‘M’ upon the appearance of the second R.
3.2.3.2 Aural training
Both groups completed the same aural training task in which pictures of 24 novel objects were presented. The task had the structure of a match-mismatch task, and each trial consisted of two parts: a presentation part on which a picture of a novel object was presented at the center of the screen while its name was played (in a male voice), and a verification part on which either a matching or a mismatching picture or word (but not both), were presented. Participants’ task was to respond whether the item matched the previously presented picture or name. To make the task more engaging for the participants, as well as force them to process both the pictures and the auditory words, pictures and words presented on the verification part of the trials varied in physical properties from the pictures and words presented on the presentation part (see Figure 3.2). Namely, pictures were always presented in grey scale, while auditory words were played in a different gender voice (i.e., in a female voice). Another manipulation consisted of presenting smaller and larger versions of the pictures (50% smaller or larger than the original size), while the same manipulation for objects’ names consisted of presenting the female voice either in higher (70dB) or lower intensity (60dB) as compared to the male voice during the presentation part. These changes in physical properties of both pictures and auditory words were equally distributed over all trials. Finally, to indirectly force participants to keep the picture-word associations in their memory, the interstimulus interval between the presentation and the verification part of each trial was jittered from 500ms to 1500ms in 500ms steps. Apart from making the task more engaging, not knowing when the verification part would start (due to the unpredictable interstimulus interval) was supposed to prompt the participants to keep the picture-word association in their working memory until giving their response.
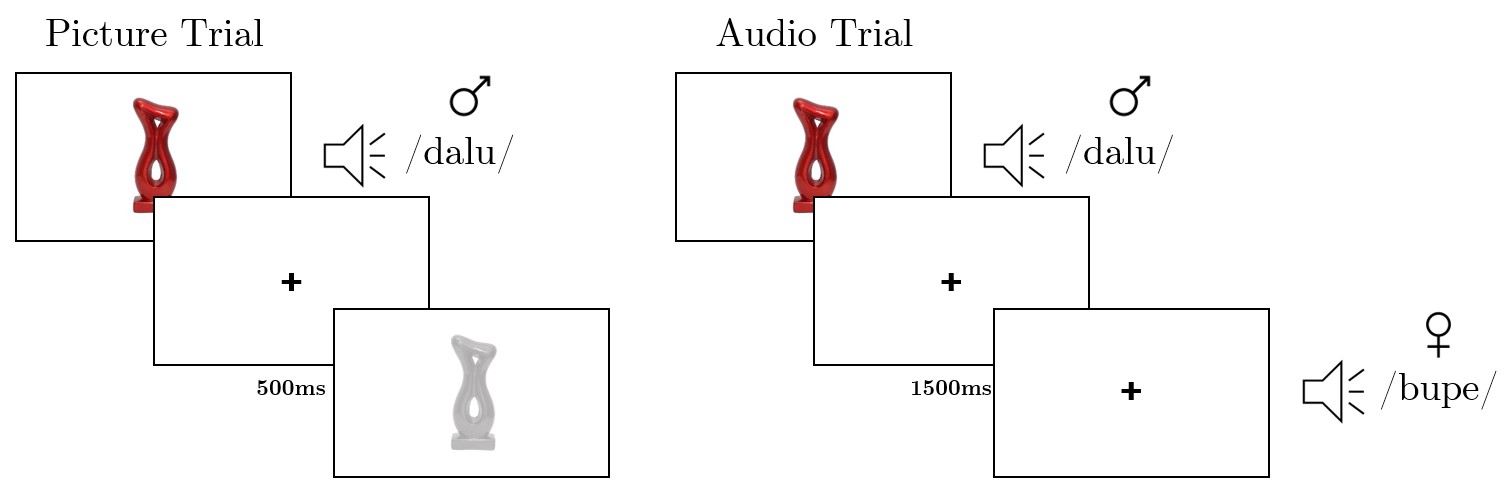
Figure 3.2: Trials of the Aural Training Blocks. The structure of the phonological training task. An example of a picture-word pair followed by a matching picture (on the left) and a picture-word pair followed by a mismatching word (on the right).
As in the previous experiments, to limit the learning load, novel objects were presented in four blocks of six. All blocks contained 75% of match trials (same picture or word as on the presentation part of the trial) and 25% of mismatch trials (different picture or word from those on the presentation part of the trial). This proportion was chosen so not to make the task, as well as learning picture-word associations, too difficult. In particular, it could be argued that presenting different pictures and words during one trial (as is the case on mismatch trials) is hindering the learning process. Therefore, within the blocks, each picture-word pair was followed nine times by the same picture or word - match trials - and three times by a different picture or word - mismatch trials, giving this way a total of 72 trials per block. After completing all four blocks, participants completed a final fifth block with the same structure (i.e., picture-word pairs were followed by either matching or mismatching pictures or words), in which all 24 pictures were presented. However, there was no manipulation in the sound intensity nor the picture size. Each of the 24 pictures was presented on four trials (two match and two mismatch trials) giving this way a total of 96 trials. The duration of the entire task was around 45 minutes.
3.2.4 Learning check
To have a measure of how well participants learned the picture-word associations, at the end of the experiment they completed a short learning check. On each trial four pictures were presented on the screen (two on the left and the right side of the screen and two pictures on the upper and lower part of the screen; see Figure 1.3) and the name of only one of them was played. Participants’ task was to choose the object which corresponded to the name that had been played. Each object was paired only once with its name, giving this way a total of 24 trials.
3.2.5 Data pre-processing and analysis
RT data from the two groups were analysed separately, since a priori we were not interested in any group interactions. Therefore, we first present data from active learners and then those from passive learners. In both tasks, RTs from the self-paced reading task were analysed following the procedure described in Section 1.2.4.1. Consequently, prior to any statistical analysis, RTs were inspected and extreme values removed (i.e., RTs below 100ms and above 2500ms; 11 data points in active and 10 data point in passive learners). In line with the Box-Cox test, RTs were then log-transformed.
Moreover, given that despite the fact that novel words had been re-recorded to make the sound clearer, participants still made errors for items starting with the sound /ʎ/. That is, some participants provided neither of the two target grapheme representations (i.e., <y> or <ll>) but a representation which does not correspond to the target sound (e.g., <hi>). Those trials for both trained and untrained items were therefore removed before the analysis (3.03% of all data points in the group of active learners and 2.55% of all data points in the group of passive learners).
3.3 Results
Preferred spellings from the pre-test spelling task for both word sets (Set A and B) are shown in Tables ?? and ?? in Appendix 3.12.
3.3.1 Learning check
The overall accuracy from the learning check phase did not differ between the groups (\(M_{active}\) = 64.1, \(SD_{active}\) = 26; \(M_{passive}\) = 62.6, \(SD_{passive}\) = 26.4; t(62) = .226, p = .822), suggesting that the type of instruction (explicit versus implicit) did not lead to different learning outcomes. Distribution of accuracy for both active and passive learners is shown in Figure 3.3.
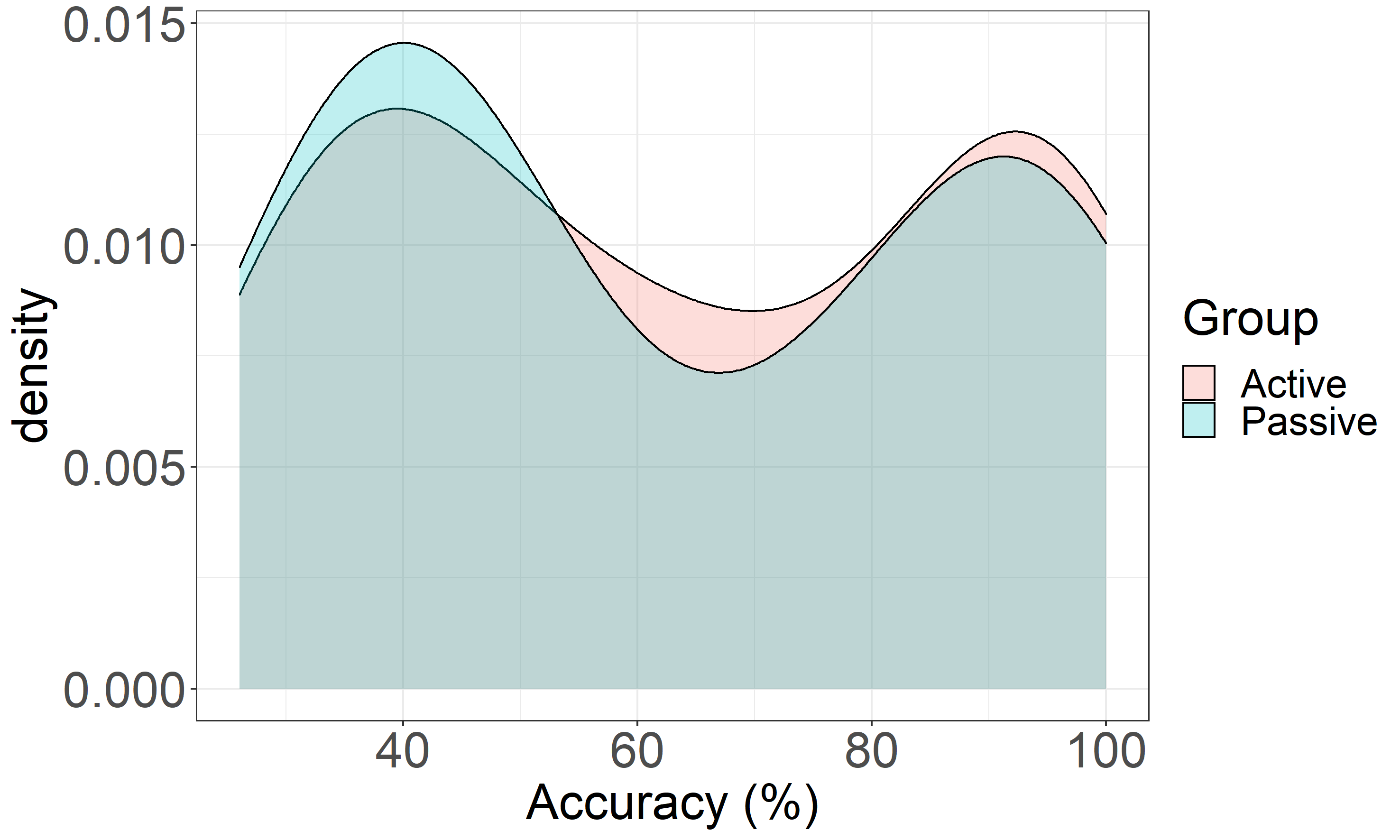
Figure 3.3: Distribution of Accuracy in the Learning Check. Distribution of accuracy for the two groups of participants (active learners are shown in pink and passive learners in blue. The two groups did not differ in their performance on the learning check task.
3.3.2 Self-paced reading
3.3.2.1 Active learners
Mean RTs for the three different spellings of both trained and untrained words, observed in the group of active learners, are shown in Figure 3.4. Distributions of RTs are shown in Appendix 3.13 (see Figure 3.10).
The model with the maximal random-effects structure justified by the data (Bates et al., 2015), looking at both trained and untrained words, included by-participant random intercepts as well as by-participant random slopes for the factor training and the Spelling1vs3 contrast (see Table 3.2). The model showed no effect of Training (β = -.023, SE = .020, t = -1.18, p = .243), or Spelling1vs2 contrast (β = .029, SE = .019, t = 1.55, p = .120). However the Spelling1vs3 contrast, indicating a difference in reading unpreferred and unique spellings, was significant (β = .045, SE = .020, t = 2.21, p = .033). Contrary to Experiment 1, there was no interaction between Training and Spelling1vs3 contrast (β = -.038, SE = .039, t = -.987, p = .323). The same was the case for the interaction between Training and Spelling1vs2 contrast (β = -.038, SE = .038, t = -1.00, p = .316).
| Fixed effects | Estimate | SE | t value | p |
|---|---|---|---|---|
| (Intercept) | 5.94 | 0.048 | 124 | < .001*** |
| Training | -0.023 | 0.020 | -1.19 | 0.243 |
| Spelling1vs2 | 0.029 | 0.019 | 1.55 | 0.120 |
| Spelling1vs3 | 0.045 | 0.020 | 2.21 | < 0.05* |
| Set | -0.149 | 0.116 | -1.28 | 0.210 |
| Training: Spelling1vs2 | -0.038 | 0.038 | -1.00 | 0.316 |
| Training: Spelling1vs3 | -0.038 | 0.039 | -0.987 | 0.323 |
| Random effects | Variance | Std. Dev. | ||
| Participant (Intercept) | 0.105 | 0.324 | ||
| Participant: Training (slope) | 0.004 | 0.068 | ||
| Participant: Spelling1vs3 | 0.001 | 0.033 |
Although the interaction between training and Spelling1vs3 contrast was not significant, we ran two additional models: one looking only into trained (trained words coded as 0) and the other looking only into untrained words (untrained words coded as 0), and found that the Spelling1vs3 contrast was significant within the trained (β = .064, SE = .028, t = 2.28, p = .024), but not within the untrained words (β = .025, SE = .028, t = .916, p = .361).
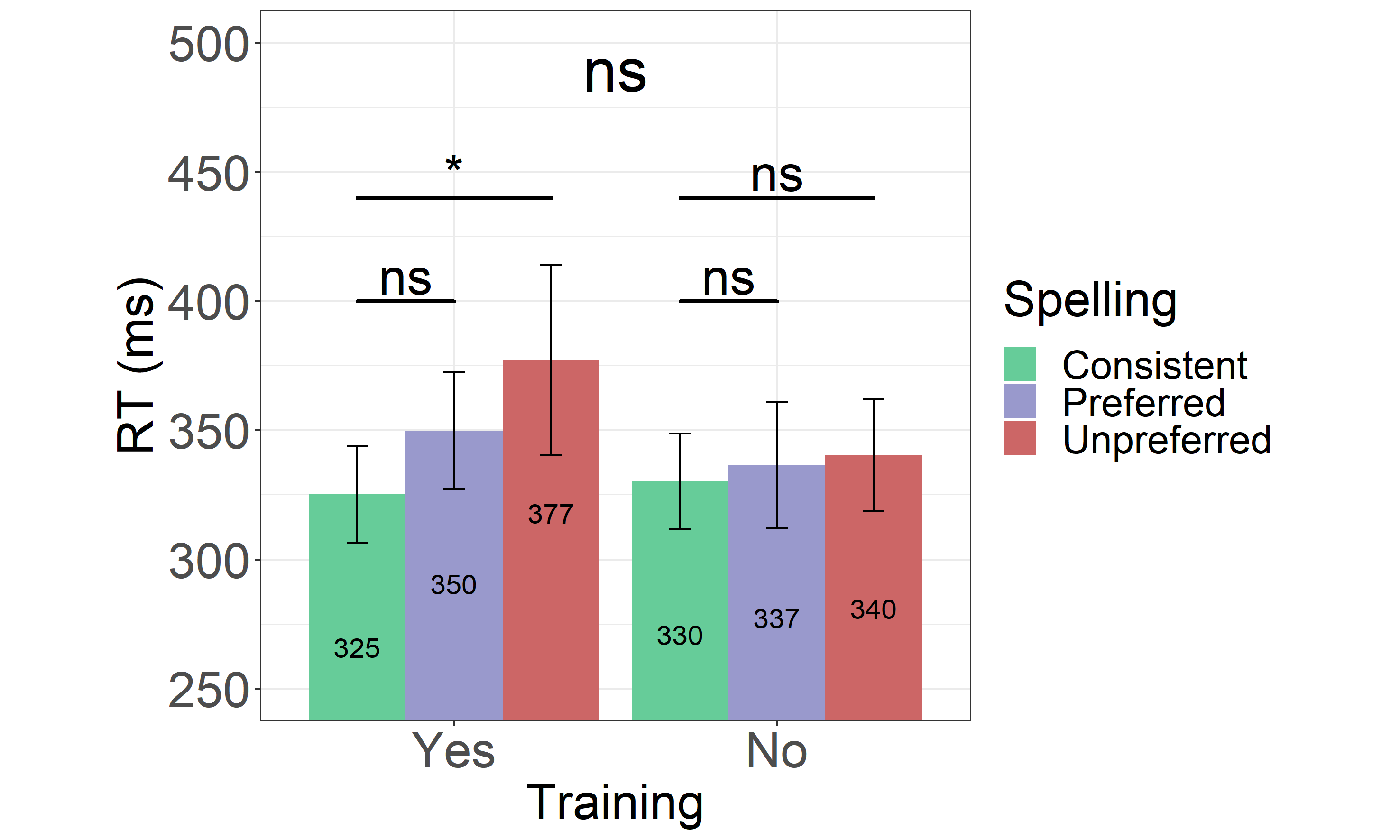
Figure 3.4: Reaction Times in the Active Learning Group From Experiment 3. Reaction times for both trained (Yes) and untrained (No) consistent, preferred and unpreferred word spellings. Error bars represent the standard error of the mean, and the numbers within the bars represent the mean RTs for each condition.
3.3.2.2 Passive learners
Mean RTs for the three different spellings of both trained and untrained words, observed in the group of passive learners, are shown Figure 3.5 and the distributions of RTs are shown in Appendix 3.13 (see Figure 3.11).
The main model looking into both trained and untrained words (see Table 3.3) showed no main effect of Training (β = -.011, SE = .021, t = -.505, p = .617), Spelling1vs2 contrast (β = -.002, SE = .022, t = -.113, p = .910) or Spelling1vs3 contrast (β = .021, SE = .035, t = .831, p = .406). Neither of the two interactions: Training and Spelling1vs2 contrast (β = .003, SE = .043, t = .069, p = .945) or Training and Spelling1vs2 contrast were significant (β = .016, SE = .043, t = .366, p = .714).
| Fixed effects | Estimate | SE | t value | p |
|---|---|---|---|---|
| (Intercept) | 5.89 | 0.072 | 98 | < .001*** |
| Training | -0.013 | 0.022 | -0.599 | 0.554 |
| Spelling1vs2 | 0.004 | 0.021 | 0.182 | 0.856 |
| Spelling1vs3 | 0.021 | 0.021 | 0.997 | 0.319 |
| Set | 0.059 | 0.144 | 0.412 | 0.684 |
| Training: Spelling1vs2 | 0.004 | 0.042 | 0.089 | 0.928 |
| Training: Spelling1vs3 | 0.010 | 0.042 | 0.245 | 0.807 |
| Random effects | Variance | Std. Dev. | ||
| Participant (Intercept) | 0.121 | 0.348 | ||
| Participant: Training (slope) | 0.005 | 0.072 |
Moreover, no differences in RTs were found within trained words: Spelling1vs2 (β = .002, SE = .030, t = .065, p = .948), Spelling1vs3 (β = .016, SE = .030, t = .532, p = .595), or the untrained ones: Spelling1vs2 (β = .006, SE = .030, t = .191, p = .848) and Spelling1vs3 (β = .026, SE = .030, t = .876, p = .381).
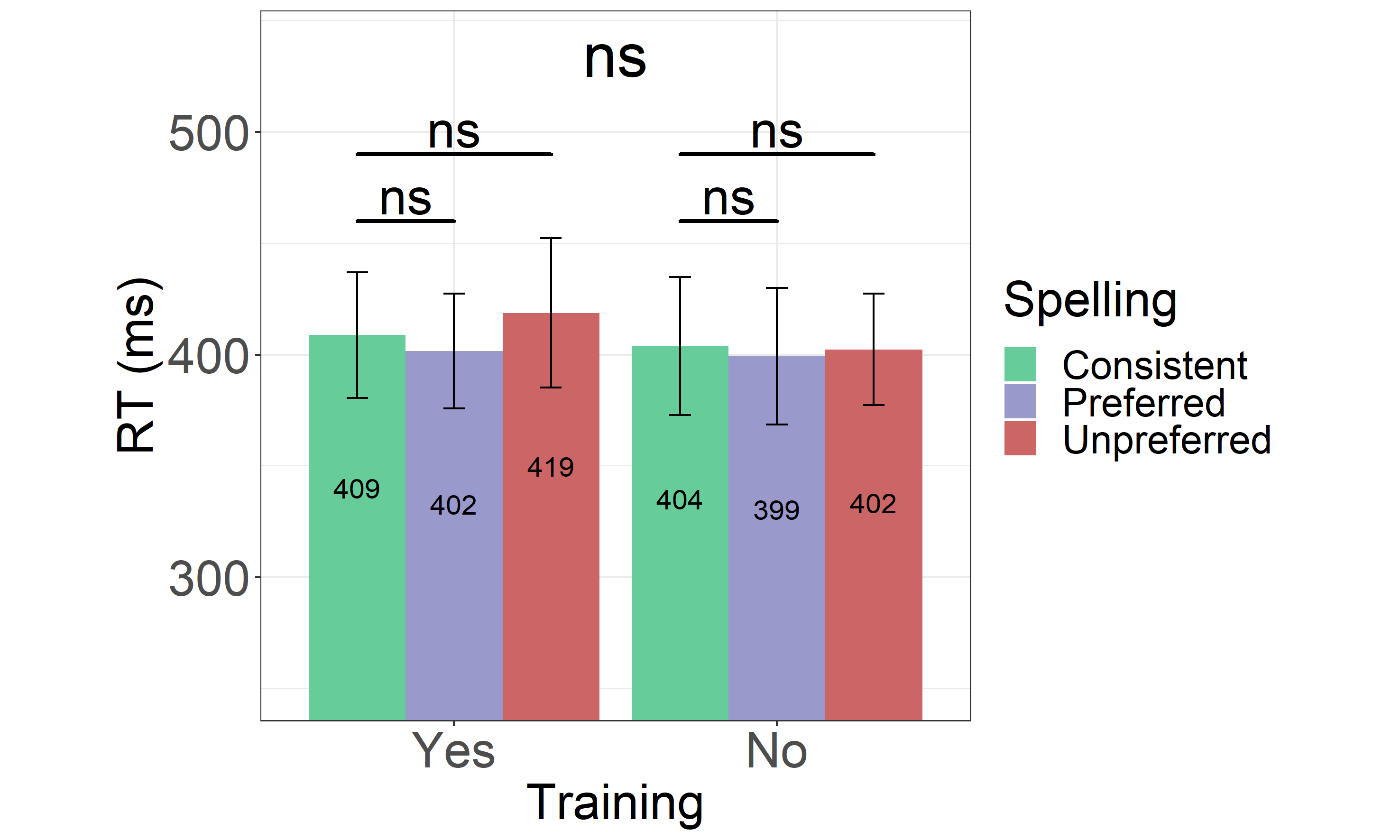
Figure 3.5: Reaction Times in the Passive Learning Group From the Experiment 3. Reaction times for for both trained (Yes) and untrained (No) consistent, preferred and unpreferred word spellings. Error bars represent the standard error of the mean, and the numbers within the bars represent the means for each condition.
3.3.2.3 Exploratory analysis
To better understand the pattern of results from the two learning groups, three additional exploratory analysis (not planned apriori) were conducted. The first one compared RTs for unique, preferred and unpreferred spellings across the two groups of learners within the same model. The second one compared the data from Experiment 1 to those of active learners from the present study. In addition, to explore whether the absence of a significant interaction between Training and Spelling1vs3 contrast in the group of active learners is due to the lack of statistical power in the present study, we ran a power analysis based on the estimates from Experiment 1. This enabled us to see how many participants would be needed to detect a significant interaction in a future study.7
3.3.2.3.1 Combined group analysis
To test whether there is an effect of group, and precisely, type of learning, on reading previously acquired spoken words with unique, preferred and unpreferred spellings, a combined analysis with both groups of learners was performed. The fixed factor Learning Group was deviation coded (active learners coded as -0.5, passive learners coded as 0.5).8
Apart from the effect of Learning Group (β = -.003, SE = .0009, t = -2.71, p = .007), showing that reading times in the group of active learners (M = 348, SD = 234) were overall faster than those observed in the group of passive learners (M = 404, SD = 258), none of the main effects or interactions were found to be significant (p > .05).
3.3.2.3.2 Comparison with Experiment 1
To compare reading latencies for trained and untrained unique, preferred and unpreferred words observed in the group of active learners from the present study to those from Experiment 1, the same model as the one described above, but with the factor Experiment (Experiment 1 coded as -0.5, Experiment 2 coded as 0.5) was run.
The model showed a significant effect of Experiment (β = -.228, SE = .075, t = -3.032, p = .003) since overall reading times for active learners were faster in the present (M = 348, SD = 234) as compared to the first study (M = 421, SD = 209). In addition, the model detected the effect of Spelling1vs3 contrast (β = .041, SE = .015, t = 2.78, p = .006). None of the interactions were significant (p > .05).
3.3.2.3.3 Power analysis based on data from Experiment 1
The power analysis based on the data from Experiment 1 was performed by creating a dataframe with the same design as in Experiment 1, using the designr package (Rabe et al., 2021) in R. Next, 400 novel data sets based on the estimates obtained in Experiment 1 (100 per sample size, ranging from 24 to 96 in steps of 24) were simulated, and the model with the maximal random-effects structure (including both by-participants and by-item random intercepts, by-participants random slopes for training, two contrasts of interest and their interaction with training, as well as by-item random slops for the factor training) was run on each of the datasets. The power per sample size was then calculated as the percentage of times a significant interaction between Spelling1vs3 contrast and Training was obtained (e.g., obtaining a significant interaction 60 out of 100 times would indicate a power of 0.6 for that particular sample size).
Power for a potential future study as a function of sample size (from 24 to 96 in steps of 24) is shown in Figure 3.6.
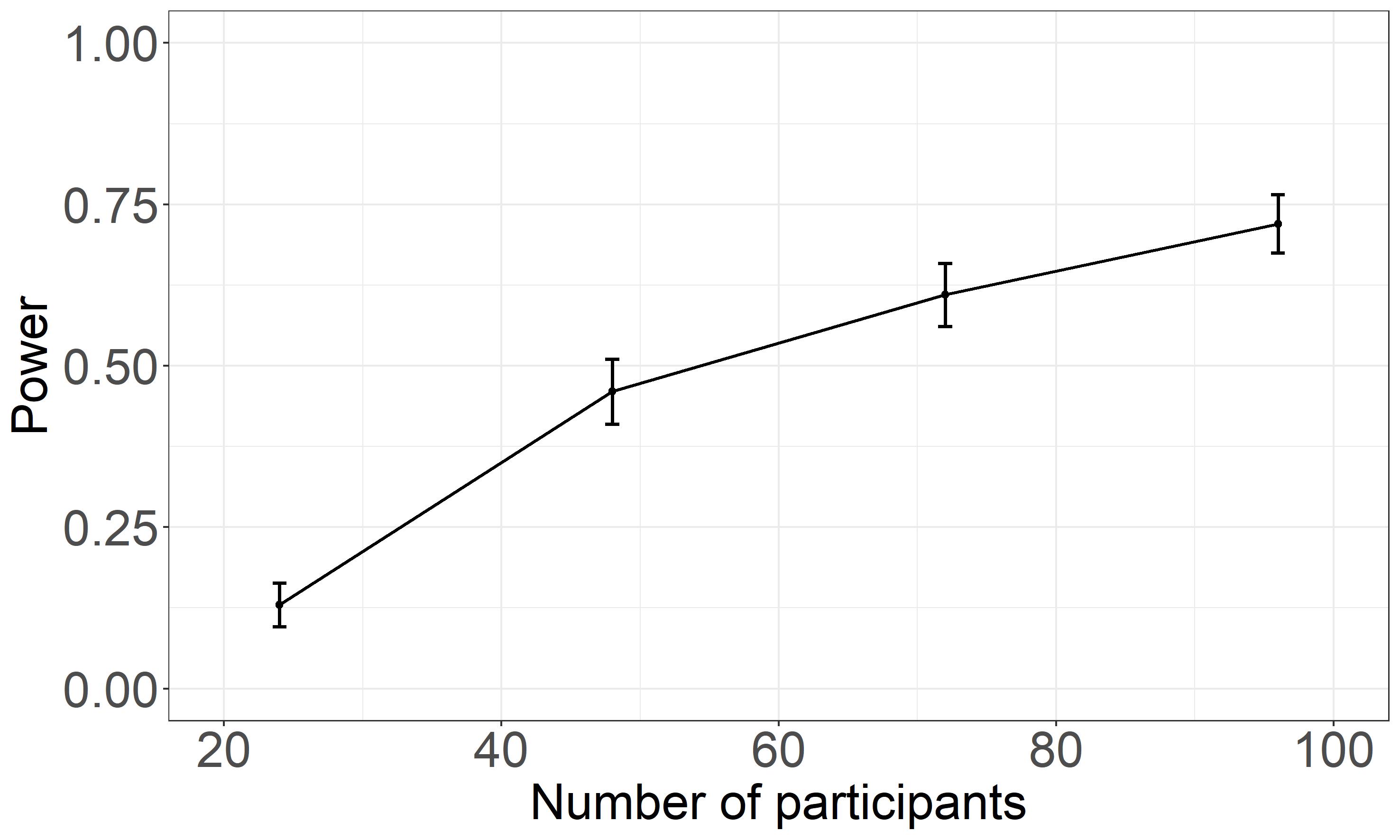
Figure 3.6: Power as a Function of the Sample Size. Power analysis was performed on the data from Experiment 1.
Based on this power analysis, we conclude that in order to detect the significant interaction between Spelling1vs3 contrast and Training with a power of 0.7 we would need at least 96 participants, which is almost three times more participants than tested in the present study.
3.4 Discussion
The final experiment of the present thesis further investigated the mechanism by which novel phonological representations are converted into orthographic ones during auditory word learning. In particular, we tested whether the process of generating orthographic skeletons is unconscious and automatic, implying that it functions any time a novel word is acquired, or whether it is voluntary in nature. The latter would suggest that participants engage in generating orthographic skeletons consciously every time they need to learn a new spoken word. To that end, two groups of Spanish speakers were tested reading previously acquired spoken words with a unique or two possible spellings. Importantly, the groups differed in whether they acquired novel words through explicit or implicit instruction. That is, although the aural training task was exactly the same for both groups, active learners - just like participants tested in Experiments 1 and 2 - received explicit instructions and were aware that they had to learn novel picture-word associations. Passive learners by contrast, completed the same aural training task thinking their perception of novel objects was being tested. These differences in participants’ awareness of the learning process allowed us to test the automaticity of the mechanism responsible for the creation of orthographic skeletons.
Overall, the results show differences in reading aurally trained words between the two groups of learners. While no significant effects in reading aurally trained words with unique, preferred or unpreferred spellings were found in the passive learning group, active learners showed a similar pattern to the one reported in Experiment 1. Even though no interaction between spelling and training was found (as was the case in both Experiment 1 and 2), the difference between reading words with unique as compared to those presented in the unpreferred of the two spellings was significant only within the set of trained words. We take this difference within trained words as evidence that active learners did generate orthographic skeletons, and this, regardless of the number of possible spellings. In line with the orthographic facilitation literature showing positive impact of orthography novel word learning, active learners may have consciously chosen to do generate orthographic skeletons in order to facilitate the word learning process. By contrast, given that participants from the passive learning group did not show differences in reading previously acquired words with a unique or two possible spellings, we do not have reasons to believe that they had generated orthographic skeletons as a result of the aural training. Importantly, since they seem to have learned the novel words equally good as active learners, their newly acquired word representations were probably entirely phonological in nature. Having no explicit reason to generate orthographic representations in addition to the phonological ones, passive learners did not automatically activate their orthographic knowledge during the training phase.
Apart from providing more insight into the nature of the process responsible for generating orthographic skeletons, findings from the present experiment expand on the previous research reporting orthographic effects in spoken language processing. Throughout this thesis we relied on orthographic (in)consistency to test the involvement of orthography in spoken word learning. Along with the studies conducted by Wegener and colleagues (Wegener et al., 2018, 2020) the work presented here thus reveals another way in which orthographic knowledge affects speech processing. By making use of their sound-to-letter mapping knowledge, skilled readers are able to generate preliminary orthographic representations even in the absence of orthography. However, previous literature showing the impact of orthography on speech perception, argues that the orthographic effects are automatic in nature. There is indeed evidence showing that upon hearing spoken words, their orthographic counterpart are automatically co-activated (Chéreau et al., 2007; Perre & Ziegler, 2008). Data from the present experiment by contrast, suggest that in spoken word learning orthographic effects may not be automatic but could actually be driven by a strategic and hence voluntary process. Being confronted with a novel spoken word will not automatically lead to the creation of its orthographic analog. As they are generated by a voluntary process (i.e., via explicit instruction) these preliminary orthographic representations may also not affect auditory perception in the same way already familiar words do. Future research could set out to explore the qualitative difference between orthographic representations generated through visual exposure (i.e., reading) to those generated in the absence of orthography.
To explore the absence of the interaction between training and spelling, we conducted a power analysis on data and estimates from Experiment 1. This way we were able to obtain the information about the statistical power for a future study employing the same design, as a function of the sample size. As shown in Figure @ref{fig:expe3power}, to detect a significant interaction with a power of 0.7, we would need at least 96 participants, which compared to 32 participants tested in the active learners group, implies that the present study did not have enough power to detect the interaction we were interested in. Another potential reason for the absence of the significant interaction may be linked to differences in learning tasks between this and Experiment 1. Although we tried to make the two studies as similar as possible, we had to come up with a task that would at the same time allow us to test implicit word learning. The task we employed to test both explicit and implicit learning was consequently more difficult than the one used in Experiments 1 and 2. Firstly, the task used in the present study was twice as long as the one used in the first two studies. Moreover, each trial of the aural training task used in the present study consisted of two parts (i.e., presentation and verification part). Finally, the learning task used in the present study was also more engaging, as participants had to monitor and process more aspects of the pictures and words presented to them (e.g., words played in different gender voices, pictures shown in different sizes and colours, etc.). That learning tasks differed in their difficulty is supported by differences in overall accuracy from the learning check task, which was lower here than in both Experiment 1 and 2 (more than 90% in the first two as compared to 62% in the present study). It is important to note however, that while learning check consisted of 144 trials in the first two experiments (each picture was paired with its name on 6 different trials), in the present study each picture was paired with its name only once (24 trials in total). This means that participants in the first two experiments had more occasions to improve their overall accuracy score. As a result, the two tasks are not comparable and we cannot conclude much based on the observed differences in learning scores. Having said that, although the learning accuracy may be considered lower in the present as compared to the previous two studies, it is reassuring that active and passive learners did not differ in their overall learning rate. Given that the participants from the passive learning group did not know they were supposed to learn the picture-word associations, one could expect to see lower learning rates than in the active learning group of participants, since the latter were explicitly instructed to focus on picture-word associations as their performance would later be tested. The fact that no differences were found, and that learning rate was almost the same across the two group (62% compared to 64% in the active learners group) suggests that the paradigm we developed for the purpose of the present study could be used in future research to study mechanisms involved in explicit and implicit word learning.
Although implicit and explicit learning mechanisms per se were not of the main interest for the present study, differences and similarities between the two groups of learners should nevertheless be discussed in relation to the previous literature. Based on both behavioural (Sobczak & Gaskell, 2019) as well as neuroimaging data (Batterink & Neville, 2011) showing that acquiring novel words takes more time in implicit than in explicit learning contexts, it was somewhat surprising that after a relatively short aural training, no differences in learning scores were found between the groups. In fact, distributions of the learning scores were almost identical in the two groups. This finding could reflect the failure of explicit learners to properly acquire novel word forms. Alternatively, the absence of a difference between the groups could also stem from methodological issues raised in the previous paragraph. It could be the case that with more learning check trials, a difference between the groups would emerge. Importantly, the findings from the present study add to the previous literature by showing another difference between explicit and implicit learning. While explicit spoken word learning may lead to the creation of (preliminary) orthographic representations, implicit acquisition of novel phonological word form does not involve the activation of orthography.
A somewhat surprising finding was a significant difference in total reading times observed when data from the group of active learners from the present study were compared to those obtained in Experiment 1. Namely, even though the pattern of reading times was similar across the two studies, indicating that participants in the present study, similarly to those tested in Experiment 1, generated orthographic skeletons during the learning phase, active learners from the present experiment were overall faster to read both trained and untrained words. As previously discussed, the two studies employed learning tasks that differed in their overall difficulty and duration. Since the task was more engaging and it took them more time to complete, participants in the present study could have been eager to complete the experiment thus leading to their faster performance on the reading task. However, it is important to keep in mind that the present study included a sample size almost twice as small as the one from Experiment 1. Since the variability in reading times was large (see Figure 3.4), the pattern of results observed in the present study may therefore be influenced by a few extremely fast participants. Testing more participants with the aim to achieve more power and reach at least the same sample size as in Experiment 1, will help clarify reading time differences.
To sum up, the final experiment of the present thesis investigated the nature of the mechanism responsible for the creation of orthographic skeletons during spoken word learning. Although more participants need to be tested in order to draw any strong conclusions about the automatic or voluntary nature of skeleton generating mechanism, data from the present experiment suggest that generating orthographic skeletons may actually occur only in active learning contexts. This means that the effects described so far may not be inherent to the cognitive system but may actually be under voluntary control. Alternatively, the process of generating orthographic skeletons as a result of implicit learning may need more time.
References
Note that we are calculating power for a future study based on the estimates from Experiment 1, and not the power of the Experiment 1. The latter is pointless given that the p values are already known (Hoenig & Heisey, 2001).↩︎
The model had the following structure: logRT~1+Training:Spelling1vs2:LearningGroup + Training:Spelling1vs3:LearningGroup + Set + (1+training_coded+group3_1||participant)↩︎