Chapter 2 The role of orthographic depth in spoken word learning
Work presented in this chapter is based on:
Jevtović, M., Antzaka, A. and Martin, C.D. (in press). Déjà-lu: When orthographic representations are generated in the absence of orthography. Journal of Cognition
2.1 Introduction
In the previous chapter we obtained further evidence for the orthographic skeleton account by showing that orthographic skeletons are generated even for words with two possible spellings. This finding suggests that the mechanism driving phoneme-to-grapheme mappings, which in return lead to the creation of orthographic skeletons, functions even under uncertainty caused by two possible spelling options. In addition, we showed that participants tend to follow their own spelling preferences, rather than statistical properties of the language, when generating orthographic representations for newly acquired spoken words. However, to test the leniency of this process, and see whether orthographic skeletons are generated even when there is uncertainty regarding novel words’ spellings, we had to control for the number of possible spellings. This was done by creating words with unique, or only two possible spellings. Given that suchlike manipulation was not feasible in a highly inconsistent language like English, we tested adult speakers of Spanish. Consequently, the obtained results may very much be limited to the speakers of transparent languages. Indeed, Spanish is a language in which, in most cases, the predicted spelling matches the real one. Due to the overall low risk of error, speakers of transparent languages could be more prone to generate orthographic representations even when more than one spelling is possible. By contrast, speakers of opaque languages such as English, may refrain from generating orthographic skeletons since the probability of generating a correct one (i.e., the one that will match the real spelling) is lower. In the second experiment we expand on these findings by testing how generalisable they are. In particular, we set out to investigate whether generating orthographic skeletons for words with two spellings occurs even when the overall probability of generating an incorrect representation is high, as is the case in opaque writing systems. If orthographic representations are generated even when the risk of generating an incorrect representation is high, this could mean that generating preliminary orthographic representations during spoken word learning is somehow beneficial for the cognitive system. Indeed, the incidental finding from Experiment 1 showing a positive link between participants’ tendency to generate orthographic skeletons and later recall of words with unpreferred spellings, points out to a potentially beneficial role of generating orthographic expediencies in spoken word learning.
2.1.1 Orthographic (in)consistency
The term orthographic (in)consisteny is often considered as being unidirectional, since its most common meaning refers to the degree of print-to-speech (ir)regularity. Nevertheless, languages vary not only in how consistent spelling-to-sound mappings are (feedforward consistency; see Figure ??) but in how phonology is represented in spelling as well (Schmalz, Marinus, Coltheart, & Castles, 2015). As a result, these two types of (in)consistencies differentiate between languages that are: inconsistent for both spelling and reading (e.g., English; see Ziegler, Stone, & Jacobs, 1997), inconsistent for spelling but consistent for reading (e.g., French; see Ziegler, Jacobs, & Stone, 1996), consistent for spelling but inconsistent for reading (e.g., Danish; Elbro & Pallesen, 2002) and finally, languages that are consistent for both spelling and reading (e.g., Spanish; Defior, Martos, & Cary, 2002).

Figure 2.1: Sound-to-Spelling and Spelling-to-Sound Mappings Across Languages. On a scale comprising both spelling-to-sound as well as sound-to-spelling (in)consistencies, French is situated between Spanish (double consistency) and English (double inconsistency), since it is (in)consistent in only one way.
According to this classification Spanish and English (languages in which the orthographic skeleton hypothesis has been tested so far) vary on two dimensions: spelling-to-sound and sound-to-spelling consistency (see Figure 2.1). By contrast, French is consistent on one, but inconsistent on the other dimension: Compared to Spanish, French orthography is highly inconsistent for spelling (sound-to-spelling inconsistency). Since many phonemes map onto more than one grapheme (e.g., the vowel /o/ has at least three possible grapheme representations <o>, <au> and <eau>) predicting the correct spelling of a newly acquired French word comes with higher degree of uncertainty than in Spanish. This property makes French more similar to English when it comes to spelling. At the same time, French is highly consistent for reading (spelling-to-sound consistency). Indeed, relying exclusively on grapheme-to-phoneme conversion rules when decoding a novel word in French will in the majority of cases lead to the correct pronunciation. This property makes French more similar to Spanish when it comes to reading. Therefore, while English represents a case of double inconsistency, since it is inconsistent for both spelling and reading, and Spanish represents an example of double consistency, French is only inconsistent in one direction. This one-direction inconsistency makes French a perfect candidate for investigating whether orthographic skeletons are generated even when predicting the correct spelling comes with a higher degree of uncertainty, as it allows us to control for spelling-to-sound consistency.
2.1.2 The present study
Experiment 2 had two goals. As a first, and main goal, we set out to test whether orthographic skeletons are generated even when, due to the properties of the writing system, predicting the correct spelling comes with a greater risk of error. The second, and exploratory goal of the study, was to further inspect the observed link between individual tendency to generate orthographic skeletons during spoken word learning and later recall of these newly acquired words.
2.1.2.1 Main goal of Experiment 2
By testing adults with French as their first and dominant language on exactly the same experimental paradigm used with Spanish speakers, we were able to investigate whether orthographic representations for novel spoken words with multiple spellings are generated even under higher degree of uncertainty. The study had exactly the same structure as the one conducted with L1 speakers of Spanish: A group of French speakers was first asked to spell all novel words that were to be used in the experiment (target and filler novel words). Two weeks later, without knowing that the two experimental sessions were associated, they were trained on a set of 24 novel words. After this aural training, trained and untrained words were presented in short sentences. Importantly, the words participants had been trained on were presented in their unique or one of their two possible spellings (preferred or unpreferred).
Based on both the results from Experiment 1 as well as those reported by Wegener et al. (2018; 2020), we predicted one of the following two outcomes:
if orthographic skeletons are generated even for words with more than one possible spelling, reading times for previously acquired words with a unique and those presented in their preferred spellings should not differ. Trained words presented in their unpreferred spellings should however, yield longer reading times. This slowing down should occur since there will be a mismatch between the orthographic skeleton participants generate and the spellings they will later be presented with;
if, however, orthographic skeletons are generated only when there is low risk of generating an incorrect expectation (i.e., only in fairly transparent languages), aurally trained consistent French words should be read faster than the inconsistent ones altogether;
Importantly, in both cases, there should be no differences in reading words from the untrained set, thus yielding a significant interaction between training and spelling. This interaction should, in line with Wegener et al. (2018; 2020), be driven by a facilitation present when reading previously acquired words (only consistent or both consistent and preferred). Alternatively, as in Experiment 1, the same interaction could also stem from longer reading times (i.e., inhibitory effect) present only for inconsistent spellings (all or only unpreferred inconsistent).
2.1.2.2 Exploratory goal of Experiment 2
Our secondary goal was to further explore the link between participants’ tendency to generate orthographic skeletons and their performance on the final picture naming task. To better understand this link, we looked at whether it is modulated by another construct related to spoken word learning, namely, the phonological short-term memory (PSTM) capacity. Previous research shows that better PSTM capacity, which represents a person’s ability to temporarily store phonological information, is associated with better spoken word learning both in children (Gathercole, 2006; Gathercole & Baddeley, 1989) as well as adults (Baddeley, Papagno, & Vallar, 1988). However, the link between PSTM and spoken word learning declines as children get older and gain access to more advanced word learning mechanisms (e.g., comparison with similarly sounding familiar words; see Gathercole, 2006). Interestingly, this decline also overlaps with the official onset of reading. We therefore hypothesized that the decline could, at least partly, be due to the development of the mechanism by which orthographic skeletons are generated. As orthographic knowledge increases, and with it the ability to generate orthographic skeletons, PSTM may be less involved in word learning.
Based on the previous literature, we expected participants with better PSTM capacity to recall better the names of the novel objects at the end of the experiment. At the same time, we expected to replicate the positive correlation between the OSE and word recall. However, if generating orthographic skeletons is indeed modulating the relationship between the PSTM and spoken word learning, a significant interaction between PSTM and OSE in predicting word recall should be observed. The two in combination should thus be important predictors of word recall. Alternatively, tendency to generate orthographic skeletons and PSTM capacity may be independent from each other. They may actually represent somewhat compensatory mechanisms available once reading has been acquired. If this is indeed the case, there should be no interaction between the two in predicting word recall. Any positive correlation observed between generating orthographic skeletons and word recall should be independent from the positive correlation between PSTM and word recall.
2.2 Methods
2.2.1 Participants
Following the same criteria as in Experiment 1 (see Section 1.2.1), we aimed to collect usable data from approximately 48 participants. However, although a total of 55 participants completed two experimental sessions, due to technical issues with their internet connection, data from five participants failed to be transferred to the server. Additional four participants were removed due to low accuracy in the learning phase (<70%).6 Therefore, we present data from 46 (39 female) participants aged between 18 and 35 years (M = 22.8, SD = 2.63) who completed both sessions within 10 to 14 days delay between them. Participants were recruited via announcements posted on social media (e.g., student Facebook groups and Twitter). Participants were given a detailed description of the study before confirming their participation. All participants had French as their first and dominant language and all completed a questionnaire on their language skills and habits before starting Session 1 (see Table 2.1 for more details on participants self-reported measures of proficiency). The experiment was approved by the BCBL Ethics Review Board (approval number 060420MK) and complied with the guidelines of the Helsinki Declaration. Participants’ written consent was collected at the beginning of each experimental session.
| Mean | SD | Range | |
|---|---|---|---|
| AoA | 0 | 0 | 0-0 |
| Self-rated proficiency (0-10) | |||
| Speaking | 9.33 | 0.79 | 7-10 |
| Understanding | 9.61 | 0.576 | 8-10 |
| Writing | 8.93 | 0.998 | 7-10 |
| Reading | 9.5 | 0.753 | 8-10 |
| Note. Some participants had some basic knowledge of English, but were not proficient in any other language apart from French. |
2.2.2 Stimuli
2.2.2.1 Novel Words
Two sets of 24 five-phoneme-long CVCVC disyllabic French-like novel words were created (as in Experiment 1, they were classified as set A and B). Each set consisted of eight consistent and 16 inconsistent items (see Table 2.2). Consistent items contained phonemes with one dominant grapheme representation in French (hereafter consistent phonemes) and therefore they all had one dominant spelling (e.g., word /tunavə/ as <tounave>). Initial phonemes of all inconsistent words had two possible grapheme representations while the remaining four phonemes were all consistent. Namely, the following four phonemes were used: /ʒ/ which can be written as either <g> or <j>, /k/ which followed by /i/ or /e/ maps onto either <qu> or <k>, /f/ which can be represented with a grapheme <f> or <ph>, and /s/, which followed by /i/ or /e/ can be written with either <c> or <s>. As a result, all inconsistent words had two dominant spellings.
To make sure that consistent items would all be spelled in the same way (e.g., /tunavə/ spelled as <tounave>), while the inconsistent would be spelled in one of their two dominant spellings (e.g., /ʒebinə/ would be spelled as either <gébine> or <jébine>), ten pilot participants who did not take part in the study, completed a pretest spelling task and confirmed the consistent versus inconsistent spelling manipulation.
| Set | Consistent | Inconsistent Preferred | Inconsistent Unpreferred |
|---|---|---|---|
| A | |||
| A | /bemanə/ | /ʒebinə/ | /ʒevabə/ |
| A | /danyvə/ | /ʒinavə/ | /ʒitymə/ |
| A | /tunavə/ | /sedunə/ | /semivə/ |
| A | /mabynə/ | /simybə/ | /sibavə/ |
| A | /nypinə/ | /fapyvə/ | /fanynə/ |
| A | /vetagə/ | /fedinə/ | /fenɔgə/ |
| A | /pivadə/ | /kemagə/ | /kepydə/ |
| A | /lybavə/ | /kityvə/ | /kidunə/ |
| B | |||
| B | /badivə/ | /ʒedavə/ | /ʒenyvə/ |
| B | /devabə/ | /ʒimunə/ | /ʒitɔgə/ |
| B | /mevinə/ | /sepidə/ | /sebavə/ |
| B | /nemunə/ | /sitavə/ | /sidynə/ |
| B | /tabynə/ | /fabɔgə/ | /fapunə/ |
| B | /pinagə/ | /fenybə/ | /febadə/ |
| B | /lapyvə/ | /kenivə/ | /kepanə/ |
| B | /vinyvə/ | /kipynə/ | /kimavə/ |
| Note. Words from the inconsistent preferred group were later shown in each participant’s preferred spelling whereas words from the inconsistent unpreferred group were presented in the unpreferred spelling. | |||
Consistent words from the two sets were matched on the number of orthographic neighbors (Set A: M = .250, SD = .707 and Set B: M = .375, SD = .744, t(14) = -.344, p = .736), while for the inconsistent items, we made sure that neither of the possible spellings had more than two orthographic neighbors. All words were recorded by a female L1 speaker of French in a sound attenuated cabin using Marantz PMD661.
2.2.2.2 Novel objects
The same 48 pictures selected from The Novel Object and Unusual Name (NOUN) Database (Horst & Hout, 2016) and used in Experiment 1 served as novel objects participants were presented with in Experiment 2. Namely, the same pictures paired with Spanish items (see Table ??) were matched with their French counterparts (see Table ??; i.e., objects paired with consistent items from set A in the Spanish study were paired with consistent items from set A in the French study as well).

Figure 2.2: Novel Objects from Experiment 2. An example object from each set (set A and set B) and spelling group (Consistent, Preferred, and Unpreferred).
2.2.2.3 Sentences from the self-paced reading task
Sentences used in the self-paced reading task had the same structure as those used in Experiment 1 (see Table 1.3). They were all four-to-seven words long, and each made a reference to the object preceding it and whose name was to appear within the sentence. Sentences were matched with Spanish sentences on total number of words as well as the position where the target word appeared (see Table 2.3).
| Original sentence | English translation |
|---|---|
| Ce xxx est petit | This xxx is small |
| Ce grand xxx est joli | This big xxx is pretty |
| Ceci est un xxx gigantesque | This is a large xxx |
| Ceci est un petit xxx magnifique | This is a small fantastic xxx |
| Cet objet est un xxx minuscule | This object is a small xxx |
| Cet objet est un petit xxx magnifique | This object is one small fantastic xxx |
| Ce grand objet est un xxx magnifique | This big object is one fantastic xxx |
| Ce grand objet est un magnifique xxx | This large object is a fantastic xxx |
| Note. Due to syntactic differences across languages the position of the target word is not equivalent in the French sentences and their English translations. Exes represent the place where target words appeared. |
2.2.3 Procedure
The study consisted of two experimental sessions completed with a 10-14 days delay between them. In Session 1, participants completed a total of five tasks always presented in a fixed order. The session started with a pre-test spelling task during which participants provided their spelling preferences for all novel words (trained, untrained and fillers). They then completed two distractor linguistic tasks (i.e., a lexical decision and a word spelling task) whose role was to mask the spelling manipulation. Finally, they completed two task aimed at assessing phonological skills: a phoneme deletion task and a pseudoword repetition task. Note that for the present study, only data from the pre-test spelling and the pseudoword repetition are relevant. The other tasks will thus not be discussed further.
Session 2 had exactly the same structure as in Experiment 1. Participants first acquired a set of novel spoken words in the aural training task and were then presented with the words’ spellings in the self-paced reading task. The session ended with the picture naming task in which participants had to type the names of all previously acquired objects.
Given that the detailed descriptions of the pre-test spelling task (see Section 1.2.3.1), the aural training (see Section 1.2.3.2), the self-paced reading task (see Section 1.2.3.3) and the picture naming task (see Section 1.2.3.4) have been provided in Chapter 1, and that the phoneme deletion task was performed as part of another project, only the pseudoword repetition task will be presented in detail here.
2.2.3.1 Pseudoword repetition
The aim of the pseudoword repetition task was to obtain a measure of participants’ phonological short-term memory capacity and explore whether it correlates with participants’ tendency to generate orthographic skeletons. In this task, participants were presented with sequences of monosyllabic French-like nonwords that they first had to repeat in the same order (i.e., starting from the first until the last pseudoword of the sequence; hereafter forward repetition block) and then in the reversed order of presentation (i.e., starting from the last and going to the first pseudoword from the sequence; hereafter backward repetition block). The order of presentation of the two blocks was fixed (the forward block was always followed by the backward repetition block) and both blocks started with a sequence containing two pseudowords. The sequences gradually increased in length, going from two to eight, and two sequences of each length were presented (i.e., two sequences of two pseudowords, two sequences of three pseudowords, etc.). To make sure that pseudowords within each list sound as phonologically distinct as possible from all the other pseudowords within the same sequence, they all contained a different vowel sound, and none started or ended with the same consonant (the complete list of pseudowords used in the task is presented in Table ?? in Appendix 3.9). Along with the Orthographic Skeleton Effect score (i.e., the OSE score; see Section 1.2.4.2) and the data from the picture naming task (see Section 1.2.4.2), scores from pseudoword repetition task were used to explore the relationship between individual tendency to generate orthographic skeletons and later novel word recall.
Each trial had the following structure. First, a fixation cross appeared at the centre of the screen. After 1000ms a picture of an ear was shown. This picture indicated that the listening part of the trial was in course. At the same time, the sequence of pseudowords was played. In each sequence, there was a 750ms pause between any two pseudowords. After the last pseudoword of the sequence had been played, the picture of the ear disappeared and there was a 500ms pause before the picture of a mouth appeared. This initiated the microphone and the production part of the trial. Participants had 10 seconds to respond before the picture of the mouth disappeared signaling the end of that trial. Participants had to click on the button presented at the centre of the screen to start the next trial and hear the next sequence. At the beginning of each block two practice examples were completed. During the practice trials participants were prompted to record their response and then compare it to the correct one that was played to them after they had given their response. The entire task took participants approximately 20 minutes to complete.
2.2.4 Data pre-processing and analysis
Data obtained in the pre-test spelling task were used to determine the spellings of preferred and unpreferred items in the self-paced reading task. Spelling preferences per item are shown in Appendix 3.10 and will no be discussed further. Data from the aural training task served as an indicator of how well participants acquired the novel words they had been trained on and thus exclude those participants with accuracy below the a priori set criteria (<70% of accuracy). Consequently, only descriptive statistics for the aural training are presented. Finally, in the nonword repetition task, a total number of correctly repeated nonwords in both the forward and the backward block was calculated for each participant, and this score was then used as an indicator of their PSTM capacity. Along with the index of participants tendency to generate orthographic skeletons (OSE; see Section 1.3.3), PSTM scores were used to predict word recall in the final picture naming task (i.e., the inverse ALINE score; see section 1.2.4.2).
2.2.4.1 Self-paced reading task
RTs were analysed following the procedure described in the Section 1.2.4.1. Namely, before the analysis, raw RTs were visually inspected and data points outside of range (i.e., RTs below 100ms and above 2500ms; eight data points in total) were removed. As indicated by the Box-Cox test (Box & Cox, 1964) the RTs were then log-transformed. Finally, outlier removal was based on scaled residuals. In consequence, only statistical models performed on data without any absolute values of the scaled residuals greater than 3 are reported (1.18% of all data points were removed).
The fixed effects structure was the same as in Experiment 1: The three level factor spelling was deviation coded to create two contrasts of interest: Spelling1vs2 (consistent spellings coded as -0.33, inconsistent preferred as 0.67 and inconsistent unpreferred as -0.33) and Spelling1vs3 contrast (consistent spellings coded as -0.33, inconsistent preferred as -0.33 and inconsistent unpreferred as 0.67). The two-level factor Training was initially deviation coded (trained words were coded as 0.5 and untrained as -0.5) but then treatment coded in case of a significant interaction (reference level was coded as 0, and the nonreference as 1). Finally, the covariate Set was also deviation coded (Set A as -0.5 and Set B as 0.5).
Again, in order to avoid overfitting the models which would lead to reduced statistical power (Matuschek et al., 2017), random-effects structure was build following a parsimonious data-driven approach (Bates et al., 2015). As a result, all reported models represent the highest nonsingular converging models and include the maximal random effects structure for all experimental manipulations of interest supported by the data (see Table 2.5 for exact model structure).
2.3 Results
2.3.1 Aural training
The accuracy in all four blocks of the aural training, as well as the final check phase, was high (see Table 2.4). Importantly, there were no differences between the two sets of words in the final check phase (Set A: M = 93, SD = 7.08; Set B: M = 93.8, SD = 6.37; t(44) = .394, p = .695).
| Block1 | Block2 | Block3 | Block4 | FinalCheck | |
|---|---|---|---|---|---|
| Set A | 95.8 (4.64) | 96.9 (2.49) | 97.1 (4.29) | 95.6 (4.61) | 93 (7.08) |
| Set B | 96.4 (4.55) | 98.1 (3.19) | 95.5 (7.35) | 95.5 (5.69) | 93.8 (6.37) |
|
Note. Mean percentage of accuracy (SDs) per training block and in the final block of the aural trainig task |
2.3.2 Self-paced reading
In the self-paced reading task, participants read both trained and untrained words presented in their unique (i.e., consistent words), preferred or unpreferred spellings (i.e., inconsistent words). Mean RTs for all target words, measured relative to the onset of the word at the center of the screen, are shown Figure 2.3 and the distributions of RTs are shown in Appendix 3.11 (see Figure \(\ref{fig:RainPlotFR}\)).
The full model structure including both fixed and random effects is shown in Table 2.5. The model looking into both trained and untrained words showed no effects of either the Spelling1vs2 (β = .002, SE = .027, t = .082, p = .935) or the Spelling1vs3 contrast (β = .034, SE = .028, t = 1.22, p = .227). The main effect of Training was however significant (β = -.044, SE = .019, t = -2.24, p = .031), indicating that the trained words overall (M = 518, SD = 255) were read faster than the untrained ones (M = 554, SD = 291). Importantly, while the interaction between Training and Spelling1vs2 was not significant (β = .034, SE = .037, t = .917, p = .364), the interaction between Training and Spelling1vs3 was (β = .077, SE = .037, t = 2.05, p = .046).
| Fixed effects | Estimate | SE | t value | p |
|---|---|---|---|---|
| (Intercept) | 6.12 | 0.068 | 90.3 | < .001*** |
| Training | -0.044 | 0.019 | -2.24 | < .05* |
| Spelling1vs2 | 0.002 | 0.027 | 0.082 | 0.935 |
| Spelling1vs3 | 0.034 | 0.028 | 1.22 | 0.227 |
| Set | 0.211 | 0.135 | 1.56 | 0.125 |
| Training: Spelling1vs2 | 0.034 | 0.037 | 0.917 | 0.364 |
| Training: Spelling1vs3 | 0.077 | 0.037 | 2.05 | < .05* |
| Random effects | Variance | Std. Dev. | ||
| Participant (Intercept) | 0.206 | 0.453 | ||
| Participant: Training (slope) | 0.007 | 0.086 | ||
| Participant: Spelling1vs3 (slope) | 0.004 | 0.060 | ||
| Item (Intercept) | 0.003 | 0.059 | ||
| Item: Training (slop) | 0.002 | 0.044 |
Model looking into trained words only (by treatment coding the factor training; trained coded as 0 and untrained as 1), showed that the difference between consistent and unpreferred spellings was significant (β = .073, SE = .032, t = 2.25, p = .027). The same difference however, was not significant when only untrained words were considered (β = -.003, SE = .034, t = -.111, p = .912).
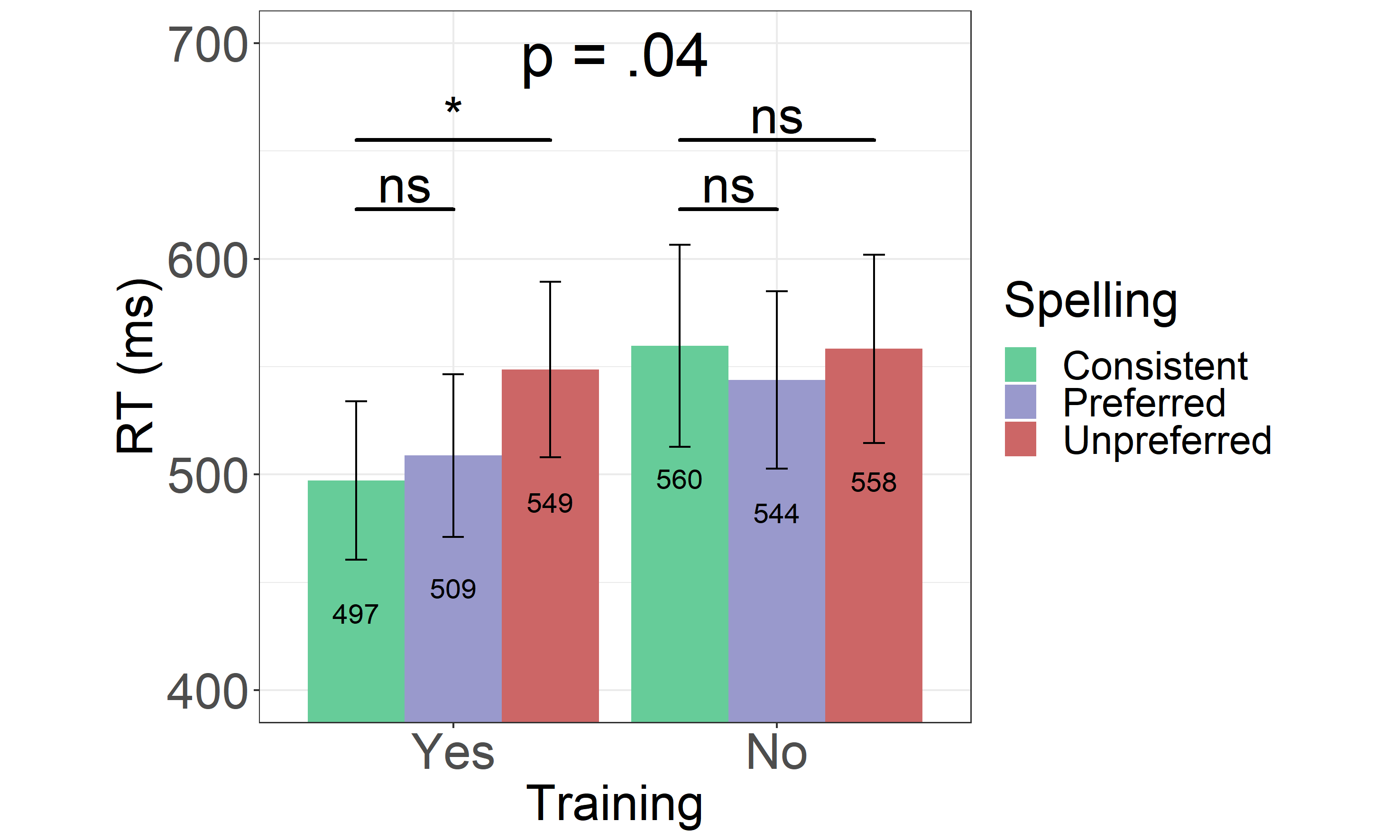
Figure 2.3: Reaction Times From the Experiment 2. Reaction times for both trained (Yes) and untrained (No) consistent, preferred and unpreferred word spellings. Error bars represent the standard error of the mean.
To summarise, the analysis of RTs showed a significant effect of aural training given that trained words overall yielded faster RTs as compared to the untrained ones. Importantly, this effect was driven by faster RTs for consistent and inconsistent preferred spellings.
2.3.2.1 Further inspection of the training effect
To further inspect the significant training effect in both the present, as well as the study conducted with Spanish speakers, two models (one per language) looking into the effect of training for each spelling condition separately were run. A custom contrast coding was used to create three contrasts of interest: the first one compared trained and untrained consistent spellings (hereafter ConsistentSpelling contrast; consistent trained coded as -0.5, consistent untrained coded as 0.5, the rest coded as 0), the second one compared trained and untrained preferred spellings (hereafter PreferredSpelling contrast; preferred trained coded as -0.5, preferred untrained coded as 0.5, the rest coded as 0), and the third one compared trained and untrained unpreferred spellings (hereafter UnpreferredSpelling contrast; unpreferred trained coded as -0.5, unpreferred untrained coded as 0.5, the rest coded as 0).
The model looking into data from French speakers included by-participants and by-item intercepts as well as by-participant random slopes for PreferredSpelling contrast. The model showed a significant effect of training for consistent spellings (β = .081, SE = .024, t = 3.35, p = .001), but not for preferred (β = .047, SE = .025, t = 1.89, p = .065) or unpreferred ones (β = .004, SE = .024, t = .175, p = .861).
The same model run with data obtained from Spanish speakers included by-participants and by-item intercepts as well as by-participant random slopes for ConsistentSpelling and UnpreferredSpelling contrasts. The model showed no differences between trained and untrained consistent spellings (β = -.019, SE = .027, t = -.694, p = .491) nor a difference between trained and untrained preferred spellings (β = -.036, SE = .025, t = -1.46, p = .144). However, the difference between reading trained and untrained unpreferred spellings was significant (β = -.063, SE = .030, t = -2.09, p = .042).
2.3.3 Exploratory analysis: The role of phonological memory in generating orthographic skeletons
To investigate the relationship between phonological short-term memory (PSTM) measured through pseudoword repetition task, and participants’ tendency to generate orthographic skeletons (OSE) on novel word retention, a multiple regression with Inverse ALINE score as a dependent variable was performed. The analysis included two predictors as well as an interaction between them: PSTM score, measured as the total number of correctly repeated pseudowords in both the forward and the backward pseudoword repetition task (ranging from 34 to 122 of correct responses) and the OSE score, operationalized as the difference between reading aurally acquired inconsistent unpreferred and consistent words (ranging from -217ms to 475ms). Both predictors were standardized before running the model. The collinearity between them was checked with VIF.mer (Frank, 2011) and all VIFs were below 2. Finally, the model with the best fit (i.e., the model with the highest adjusted R-squared value) was the one that included both predictors along with their interaction.
The results of the multiple regression show that the two predictors and their interaction predict 28.8% of the variance in the picture naming task (R2 = .28, F(3,39) = 5.12, p <.01; see Table 2.6). OSE on its own significantly predicted the inverse ALINE score (β = .038, SE = .018, t = 2.07, p = .045), indicating that higher values of OSE lead to better recall (i.e., a higher score in the picture naming task). By contrast, the PSTM score failed to reach the level of significance (β = .029, SE = .015, t = 1.96, p = .057). However, there was a significant interaction between the two (β = .063, SE = .024, t = 2.58, p = .014). The interaction suggests that the relationship between one of the predictors and the outcome, is moderated by the other predictor. For instance, the link between OSE and the inverse ALINE score, changes as a function of the PSTM score: for low values of PSTM the increase in OSE does not lead to differences in the outcome variable (i.e., the inverse ALINE), while for the higher values in PSTM the values of the outcome increase as the OSE scores increase (see the partial plot presented in Figure 2.4 for the visual representation of the significant interaction between the predictors).
| Predictor | Estimate | SE | t | p |
|---|---|---|---|---|
| Intercept | 0.86 | 0.014 | 61.14 | <.001 |
| OSE | 0.04 | 0.018 | 2.07 | 0.045 |
| PSTM | 0.03 | 0.015 | 1.96 | 0.058 |
| OSE:PSTM | 0.06 | 0.024 | 2.58 | 0.014 |
| R2 / R2 adjusted 0.282 / 0.227 |
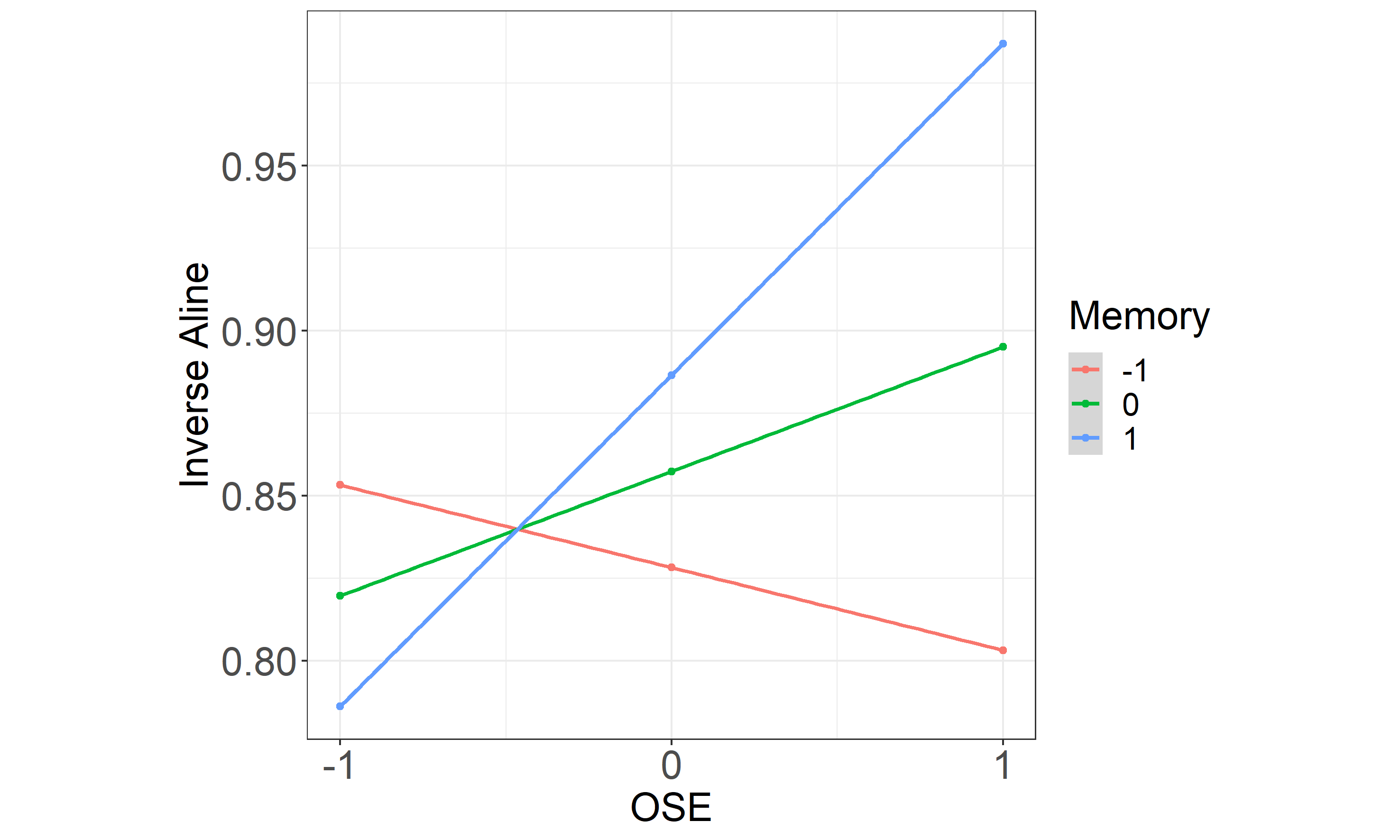
Figure 2.4: Interaction between PSTM and OSE. The moderating effect of the OSE on the relation between phonological short-term memory and word retention (Inverse ALINE similarity score). Both predictors (PSTM and OSE) are represented as z-scores.
2.4 Discussion
Experiment 2 investigated whether orthographic skeletons for words with multiple spellings are generated even in a language in which the overall probability of generating an incorrect representation is high. To test whether results from Experiment 1 can be generalised to a language with highly inconsistent sound-to-spelling mappings, we looked at how adult French speakers read novel words previously acquired through aural training. As in Experiment 1, novel words were shown in their unique or one of the two possible spellings. Overall, the results of Experiment 2 show that French speakers generated orthographic skeletons for newly acquired spoken words. This conclusion was supported by the following observations: Firstly, trained words altogether were read faster than the untrained ones. As in Wegener et al. (2018) study, this aural training advantage was driven by faster reading times for words shown in spellings matching participants’ expectations. Secondly, words presented in the unpreferred of the two possible spellings led to significantly longer reading times as compared to words with a unique spelling. This indicated that there was a mismatch between the orthographic skeletons participants had generated as a result of aural training, and the spellings they were presented with in the subsequent reading task. Finally, no significant differences in reading times were observed for untrained words shown in their unique, preferred and unpreferred spellings. These results thus show that orthographic skeletons for words with more than one spelling are indeed generated even in a language with high degree of sound-to-spelling inconsistency.
As previously discussed, in languages like French, the relationship between sounds and letters is complex since many sounds have more than one grapheme representation (Ziegler, Jacobs, & Stone, 1996). Due to the higher degree of uncertainty, and consequently higher risk of generating incorrect representations, the process of generating orthographic skeletons for newly acquired spoken words may be more conservative (i.e., restricted to situations when only one spelling is possible), or may even be suppressed in speakers of opaque languages. Here however, we show that this is not the case. French speakers exhibited a similar pattern of results as previously tested Spanish speakers. In both studies, inconsistent words presented in their unpreferred spellings yielded significantly longer reading times as compared to words with only one possible spelling. This demonstrates that French speakers were not affected by the overall complexity of sound-to-spelling mappings present in the French writing system. Furthermore, findings from French speakers are in line with those reported by Wegener and colleagues (Wegener et al., 2018; Wegener et al., 2020; see also Beyersmann et al., 2020). Across two studies, conducted with English-speaking children, Wegener and colleagues observed a significant reading advantage for previously trained novel words as compared to the untrained words. Crucially, this facilitation was driven by faster reading times found only for predictable but not for previously acquired words with unpredictable spellings. Given that the latter had more than one possible spelling, it remained unclear whether orthographic skeletons in opaque languages are generated even when, due to multiple options, the spelling of the novel spoken word is uncertain. Using the same experimental design as the one employed with Spanish speakers allowed us to control for the number of inconsistent spellings and demonstrate that orthographic skeletons for words with multiple, and hence highly unpredictable spellings, are indeed generated in languages with overall high sound-to-spelling uncertainty. The findings from the present study thus suggest that generating orthographic skeletons may be beneficial when learning novel spoken words, since it is done even when the risk of error is high.
2.4.1 Comparison with results obtained from Spanish speakers
Even though the findings from the present study are in line with those observed with Spanish speakers, an unexpected difference between the two experiments is the reversed effect of training, and in particular, the significant aural training advantage observed with French, but not with Spanish speakers. The significant training effect found in the present study stems from overall faster reading times observed for trained as compared to untrained words. This advantage in reading aurally familiar words is in line with previous research showing facilitatory effects of aural training on subsequent word reading, as well as the formation of novel orthographic representations (e.g., Álvarez‐Cañizo, Suárez‐Coalla, & Cuetos, 2019; Johnston et al., 2004; McKague, Pratt, & Johnston, 2001, Wegener et al., 2018, Wegener et al., 2020). The evidence for the orthographic skeleton hypothesis is thus found in the facilitatory effect present when reading previously acquired words shown in correctly predicted and expected spellings (see Figure 2.5). In the study conducted with Spanish speakers however, expected spellings did not differ in reading times across the two training conditions. The significant training effect was actually driven by longer reading times present only for unpreferred spellings. This slowing down thus resulted in a training disadvantage for words that did not match participants’ spelling expectations. Based on this, we can conclude that evidence for the orthographic skeleton hypothesis in Spanish is manifested as an inhibitory effect (as opposed to facilitatory) (see Figure 2.5). In other words, while Spanish speakers were slower to read previously acquired words with unexpected spellings, French participants were faster to read previously acquired words with expected spellings (see dark grey bars on Figure 2.5).
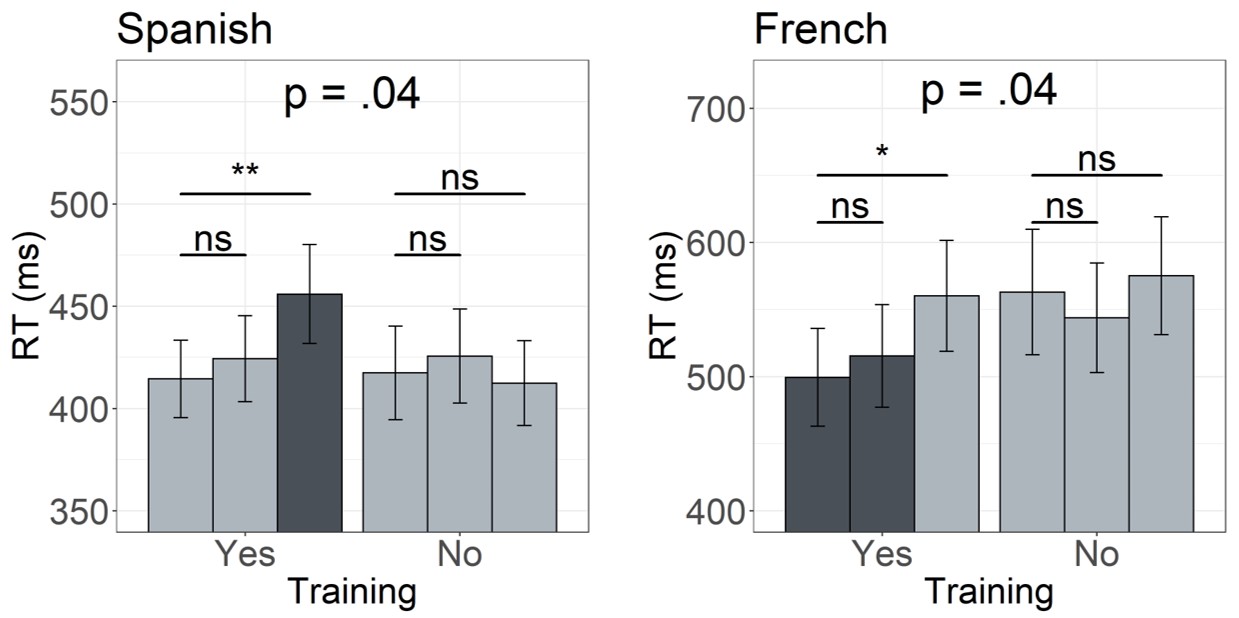
Figure 2.5: Comparison between Spanish and French Results
These differences probably stem from different experiences speakers of opaque and transparent languages have with written language. While the former are used to encountering words with multiple possible spellings, and may therefore be positively surprised whenever their expectations are confirmed, the latter (e.g., Spanish speakers) rarely have the occasion to see multiple spellings for one phonological word form. As a result, they may be more negatively surprised when encountering spellings not in line with their expectations. Moreover, this cross-linguistic comparison, showing facilitatory or inhibitory effects of generating orthographic skeletons, suggests that generating orthographic skeletons may come with a reading benefit in opaque (facilitatory effect), but not in transparent languages (inhibitory effect).
2.4.2 The link between generating orthographic skeletons on word learning
In addition to showing that generating orthographic skeletons has important consequences for subsequent word reading – either by facilitating the reading of expected spellings or by slowing down the reading of the unexpected ones – the present study reveals some consequences for spoken word learning linked to the process of generating orthographic skeletons. As seen in Experiment 1 (see Section 1.3.3), generating orthographic skeletons is associated with better recall of words shown in their unpreferred spellings: participants with larger orthographic skeleton effects were the ones who recalled more correctly the novel words presented in their unpreferred spellings. To further examine, and this way better understand the observed link between individual tendency to generate orthographic skeletons and later word recall, we set out to relate this finding to the previous literature. Based on the previous research showing that the positive link between PSTM skills and spoken word learning (Baddeley, Papagno, & Vallar, 1988; Gathercole, 2006; Gathercole & Baddeley, 1989; Gathercole, Willis, Emslie, & Baddeley, 1992) declines around the age of 8 (Gathercole, Willis, Emslie, & Baddeley, 1992), we wanted to see whether generating orthographic skeletons is at least partly related to this decline. As a result, we included a measure of PSTM in the experiment and then ran a multiple regression model predicting the outcome in the picture naming task.
The link between PSTM and the performance on the picture naming task was not significant, this way failing to replicate the results reported in the literature. However, we once again observed a positive correlation between the OSE score, representing participants’ tendency to generate orthographic skeletons, and naming accuracy. Participants who were more strongly prone to generate orthographic skeletons, recalled better the words at the end of the experiment. Importantly, there was a significant interaction between the OSE score and PSTM capacity in predicting the accuracy in the picture naming task. This interaction indicated that the link between participants’ tendency to generate orthographic skeletons and word learning was indeed modulated by PSTM: only participants with higher PSTM scores were able to benefit from generating orthographic skeletons. In other words, participants who obtained higher accuracy scores at the end of the experiment (i.e., those who remembered more correctly the words they had been trained on) did not only have higher PSTM capacity score but higher OSE scores as well. This interaction thus suggests that both generating orthographic skeletons as well as having good PSTM capacity are important for recalling (and therefore learning) novel spoken words. In line with reading time data, this finding shows that generating orthographic skeletons comes with a benefit, a word learning benefit in this case. Although it may be limited to skilled readers only, this findings shows that orthography is involved in spoken word learning even when it is not present nor relevant for the learning process.
2.4.3 Conclusion
In summary, data presented so far show that orthographic skeletons are generated even for words with multiple spellings, and that, both in languages with high (Spanish), as well as those with low sound-to-spelling consistency (French). However, we demonstrated that the consequences of generating orthographic skeletons for subsequent reading are manifested differently depending on the overall consistency of the language. Although both studies expand our understanding of the mechanism driving sound-to-spelling conversions, the nature of the mechanism by which phonological representations are converted into orthographic ones has yet to be described. Specifically, it remains unclear whether orthographic skeletons are generated unconsciously, as an automatic response to acquiring novel phonological word forms (M. Johnston, Castles, et al., 2003; Tyler & Burnham, 2006) or whether generating them represents a strategy participants employ with the aim to facilitate word learning. All previous studies testing the orthographic skeleton account employed word learning paradigms in which participants were explicitly instructed to learn novel words. Since orthography has been shown to have a facilitatory role in word learning (Rosenthal & Ehri, 2008), generating orthographic skeletons could indeed have served as a mnemonic tool helping participants in the acquisition of novel words. To adjudicate between the two possibilities and this way test whether orthographic skeletons are generated automatically during novel word learning, or whether generating them represents a strategy participants consciously employ in order to support word memorization, the process of generating orthographic skeletons should be compared in explicit and implicit learning contexts. This was indeed done in the final study of the thesis (see Experiment 3).
References
The same cut-off score as in Experiment 1.↩︎